












What Are AI Tokens? How Tokens Shape Context And AI Performance
An ai token is a small unit of text, code, or other model-readable input that an AI model processes before generating an answer. Tokens are not always whole words. A token can be a word, part of a word, punctuation mark, space pattern, number, or code fragment depending on the tokenizer and model. Tokens matter because they define how much context a model can read, how much a request costs, how long a response may take, and how stable long conversations or document workflows can remain.
Most users see prompts and answers as normal language. Large language models see sequences of tokens mapped into numbers. That translation layer explains why a short sentence, a code block, an emoji, or a multilingual paragraph may produce different token counts than a simple word count suggests. OpenAI token counting guidance explains that tokens are used for billing and usage tracking, while Google Gemini token documentation notes that generative AI models process input and output at token granularity.
This guide explains what AI tokens are, how tokenization works, what counts as a token in practice, and why token decisions affect AI performance in real systems. It also gives developers and AI teams a practical way to think about prompt design, context windows, RAG workflows, agent memory, latency, and cost control.
Quick answer: tokens shape AI performance in four practical ways: they limit how much context a model can read, influence how much an API request costs, affect response speed, and decide how much room remains for output. A product team should track tokens whenever an AI feature uses long prompts, chat history, retrieved documents, tool schemas, code, or multi-step agents.
| Decision | Token question to ask | Practical action |
|---|---|---|
| Prompt design | Are instructions clear without repeated boilerplate? | Keep role, task, constraints, examples, and output format; remove duplicated policy text. |
| Context design | Is the model seeing the right evidence, or just more evidence? | Use retrieval, ranking, summaries, and explicit source limits instead of dumping every document. |
| Cost design | Which feature, tenant, or workflow consumes the most input and output tokens? | Log usage metadata and set budgets for long chats, agents, and document workflows. |
| Performance design | Does the feature need a long answer, a fast answer, or a verifiable answer? | Reserve output tokens, choose a suitable model, and split complex tasks into smaller calls when needed. |
For teams building retrieval-heavy or agentic systems, tokens connect directly to architecture. Designveloper’s guides to advanced RAG architecture, prompt engineering best practices, and agentic AI architecture cover the same production tradeoff from different angles: the model performs better when the surrounding system sends the right context, not simply more context.
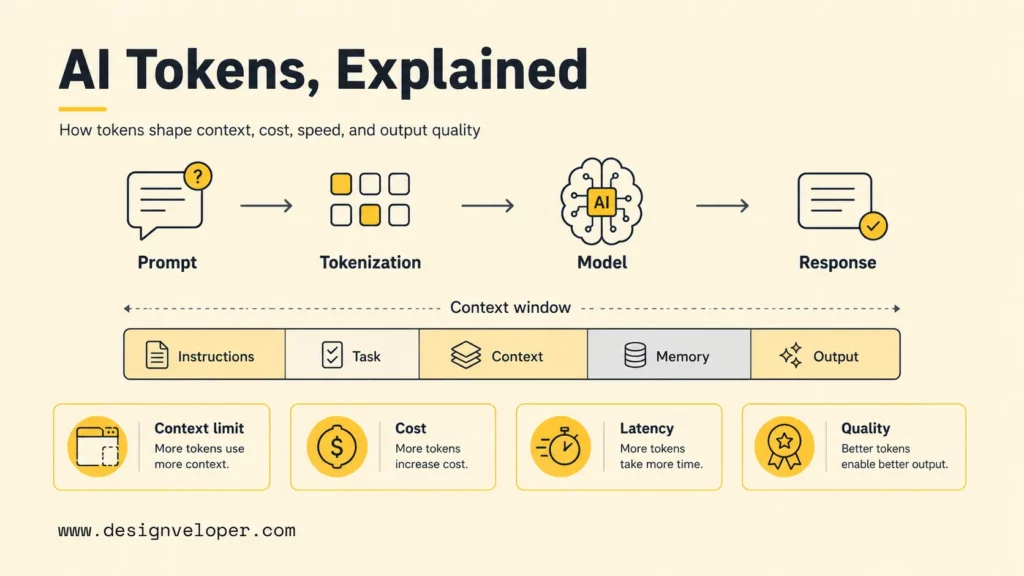
What Are AI Tokens?
AI tokens are the model-readable units that represent text and other supported input after tokenization. A model does not directly process sentences the way humans read them. The input is first broken into pieces, each piece is mapped to an identifier, and the model uses those identifiers to predict useful output.
A token may be a full word such as “project,” part of a word such as “manage” and “ment,” a punctuation mark, a newline, or a repeated code pattern. The exact split depends on the tokenizer. The OpenAI tiktoken repository describes byte pair encoding as a way of converting text into tokens and notes that language models see text as a sequence of numbers rather than raw human language.
The token layer matters because every prompt and answer consumes a token budget. If an application sends instructions, chat history, retrieved documents, tool results, and formatting rules, all of that context can count. If the model generates a long answer, the output also consumes tokens. That is why token awareness is part of production AI design, not only a billing detail.
For business teams, tokens are easiest to understand as the measurement unit behind AI attention. A model can only pay attention to a limited amount of tokenized information at once. A larger context window increases that limit, but it does not remove the need to choose the right information, compress unnecessary history, and manage cost.
A useful way to visualize tokens is to split the context window into working zones. The exact percentages change by feature, but the pattern helps teams avoid filling the entire window with input and leaving no room for the answer.
Example context budget for one AI request
The output reserve matters because a model still needs token room to respond. If a document workflow fills the window with raw PDFs, logs, and chat history, the model may truncate the answer, ignore older material, or produce a weaker response even though the context window looks large on paper.
How Tokenization Turns Text Into AI-Readable Units
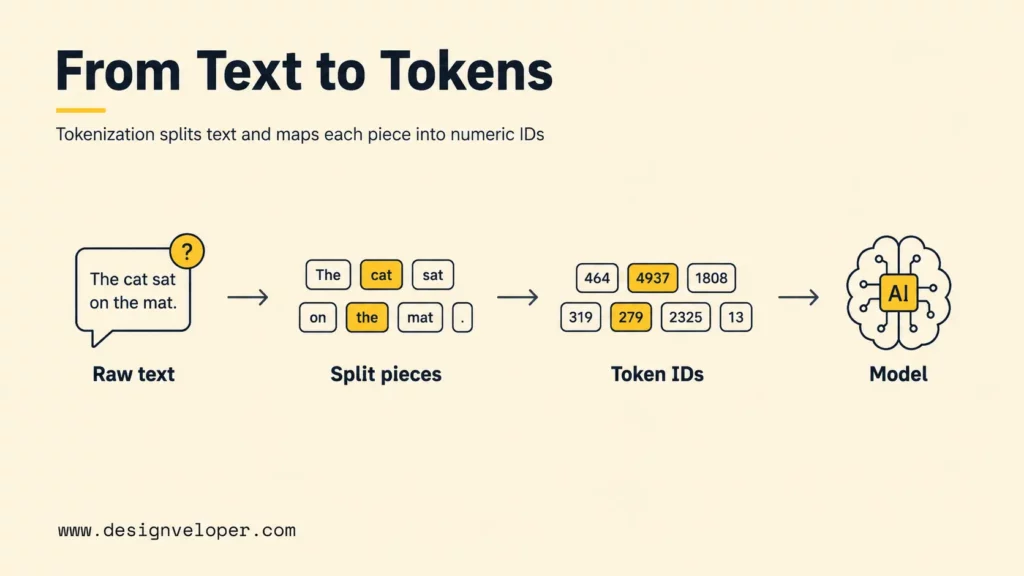
Tokenization turns text into model-readable units before the model processes it. The tokenizer applies a model-specific vocabulary and rules to split input into token pieces, then maps those pieces into numeric IDs. The model then uses those IDs during inference.
This process is invisible in most chat interfaces, but it shapes nearly every AI application. Tokenization affects how much a prompt can include, how much context a retrieval system should send, how long a response can be, and how predictable cost estimates are before a request runs.
Text Is Split Before The Model Processes It
Text is split before the model processes it because neural networks operate on numeric representations, not raw characters. The tokenizer handles that conversion. A phrase such as “AI performance” may become a small sequence of token IDs. A code snippet, URL, table, or spreadsheet-like text may produce a very different sequence.
Developers should treat tokenization as part of the input pipeline. If the application sends repeated boilerplate, long logs, duplicate chat history, or unfiltered documents, the model must spend token budget on that material before it can answer. Tokenization therefore connects directly to prompt quality.
Tokens Are Not The Same As Words
Tokens are not the same as words. A common rule of thumb is that 100 English tokens may roughly equal 75 words, but real counts vary by model, language, punctuation, formatting, and content type. Google says that for Gemini models, one token is roughly four characters and 100 tokens are about 60 to 80 English words. That is a useful estimate, not a universal law.
Numbers, code, URLs, whitespace, and non-English text can shift token counts quickly. A compact English paragraph may be token-efficient. A JSON payload, stack trace, table, or minified code block may consume more tokens than a human expects because punctuation and syntax carry meaning for the tokenizer.
Different Models Can Tokenize The Same Text Differently
Different models can tokenize the same text differently because tokenizers and vocabularies are model-specific. A prompt that fits comfortably in one model may use a different token count in another model. The difference becomes important when teams route requests across providers or switch from one model family to another.
That is why production systems should count tokens with the model’s own tool or SDK when accuracy matters. OpenAI provides an interactive OpenAI tokenizer tool, Anthropic provides Claude token counting documentation, and Google provides Gemini token counting guidance. For live applications, provider-specific counting is safer because OpenAI, Anthropic, and Google can count text, tool calls, multimodal input, and output limits differently. Estimation is useful for planning, but provider-specific counting is safer for rate limits, routing, and cost controls.
Tokens Are Mapped Into Numeric Representations
Tokens are mapped into numeric representations before the model uses them. Each token corresponds to an ID in the tokenizer vocabulary. The model then turns those IDs into internal vectors so it can model relationships, context, and likely next tokens.
This mapping explains why prompt wording can change output behavior. The model is not only reading a sentence semantically. The model is processing a sequence of token IDs shaped by the tokenizer. Small text changes can shift token boundaries, reduce ambiguity, or remove unnecessary pieces from the context window.
What Counts As A Token In Practice
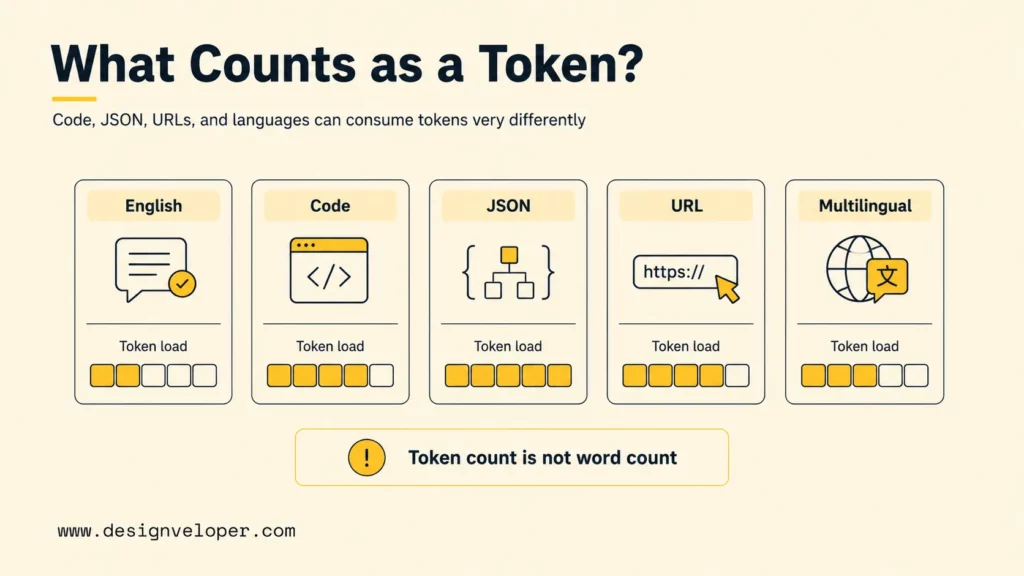
In practice, tokens can include words, subwords, punctuation, spaces, line breaks, numbers, symbols, and code fragments. Modern AI systems may also count tokens for tool definitions, function schemas, system instructions, retrieved passages, image or audio representations, and internal reasoning output depending on the provider and model.
The following examples show why token counting is not word counting:
| Input type | Why token counts can differ | Developer implication |
|---|---|---|
| Plain English | Common words may map to one token, while rare or compound words may split. | Word count estimates are usually acceptable for rough planning. |
| Code | Symbols, indentation, names, punctuation, and repeated syntax all matter. | Trim logs and code blocks before sending them to the model. |
| JSON | Keys, braces, quotes, punctuation, and repeated field names consume tokens. | Use concise schemas and avoid sending unused fields. |
| URLs and IDs | Long strings may split into many pieces. | Replace long references with short labels when the exact string is not needed. |
| Multilingual text | Token efficiency varies by language and tokenizer vocabulary. | Count with the target model instead of assuming English ratios. |
Developers should also remember that surrounding application messages count. A chat request may include the system prompt, developer instructions, conversation history, user input, retrieved context, and tool definitions. A user may type only one paragraph, while the final request sent to the model contains thousands of tokens.
Token counting becomes more complex in multimodal systems. Some providers estimate token use for images, audio, or video based on model-specific settings. Google Cloud’s Count Tokens API documentation notes that multimodal token counts can be estimated before execution, while final billing usage is available after execution metadata. That means teams should design monitoring around actual usage as well as pre-flight estimates.
Why Tokens Matter In AI Systems
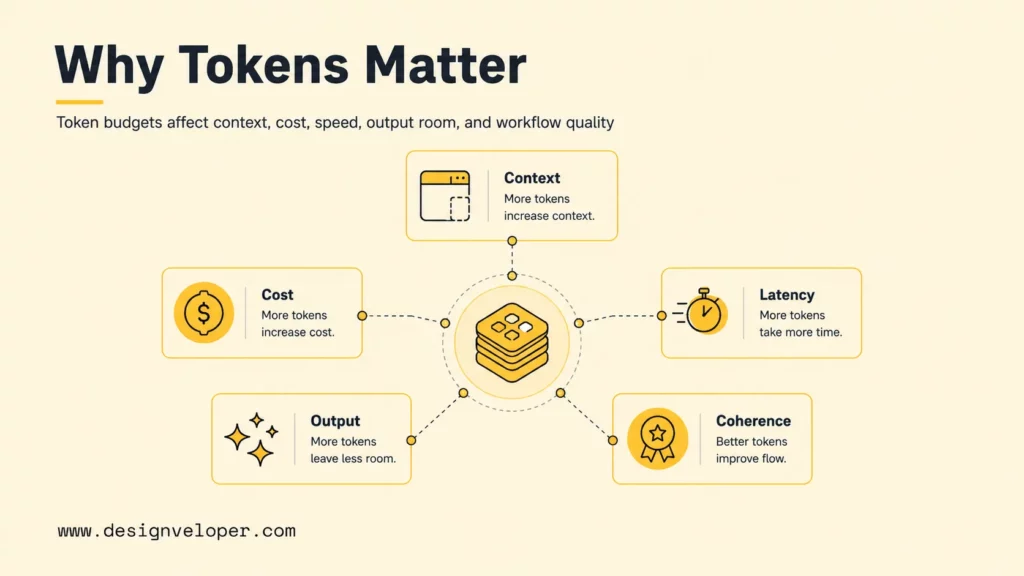
Tokens matter in AI systems because they shape capacity, cost, latency, output length, and long-context coherence. Token management is one of the practical differences between a demo prompt and a production AI workflow.
The table below turns token behavior into product decisions. It is especially useful before choosing a model, context window, RAG strategy, or agent workflow.
| Token pressure | Common symptom | Better design response |
|---|---|---|
| Too many input tokens | Higher cost, slower first response, weaker focus. | Rank retrieved passages, summarize history, trim duplicate fields, and compress tool schemas. |
| Too few output tokens | Answers stop early, skip detail, or fail to follow the requested format. | Reserve response room and set output limits based on the task type. |
| No token monitoring | Costs rise after launch without a clear owner or cause. | Track usage by feature, customer segment, route, model, and document type. |
| Long context used as memory | The assistant forgets old decisions or repeats stale details. | Store durable state separately, then retrieve only relevant summaries or records. |
| Agent loops | Multiple model calls consume more tokens than one visible answer suggests. | Set step limits, summarize intermediate state, and log token use for each tool or model call. |
Tokens Shape How Much Context A Model Can Handle
Tokens shape how much context a model can handle because every model has a context window. The context window is the maximum token budget the model can consider at once, including relevant input and sometimes generated output depending on the provider’s accounting rules. Anthropic’s Claude context window documentation explains that input and output components count toward the context window.
Large context windows can support long documents, extended chats, and multi-step agents. However, a larger context window does not guarantee better answers. Teams still need retrieval quality, prompt structure, source ranking, summarization, and validation. Poor context selection can fill a large window with irrelevant information.
Tokens Affect Input And Output Cost
Tokens affect input and output cost because many AI APIs bill by token usage. Input tokens usually cover what the application sends. Output tokens cover what the model generates. Some providers also have cached-input, reasoning, audio, image, or tool-related token categories.
OpenAI’s API pricing page shows separate prices for input, cached input, and output tokens across models and modalities. This pricing structure means a short answer can be cheaper than a long generated report, and a reused cached prompt can have different economics from a fresh prompt. Cost-aware applications should measure real usage by route, feature, tenant, and document type.
Tokens Influence Latency And Response Length
Tokens influence latency because the model must process input tokens and then generate output tokens. More input context can increase time to first response. More output tokens can increase total response time. Long tool schemas, repeated chat history, and oversized retrieved passages can all slow an application before the model writes the final answer.
Latency planning should separate input size from output length. A support classifier may need a short output and can be optimized for speed. A legal document summary may need a long input and a careful output. A coding agent may need many small model calls rather than one huge call. Token budgets help teams design the right pattern instead of treating all AI requests the same.
Tokens Help Determine How Coherent Long Interactions Stay
Tokens help determine how coherent long interactions stay because the model can only use what remains inside the active context. When a conversation, document workflow, or agent trace grows too long, older or less relevant information may be truncated, summarized, or dropped by the application.
Coherence therefore depends on memory strategy. A simple chatbot may keep recent turns only. A business assistant may summarize older conversation, retrieve relevant records, and keep explicit user preferences. A coding agent may preserve task state, edited files, test results, and decisions rather than the full raw transcript. Good token decisions keep the important state visible.
Input Tokens, Output Tokens, And Context Windows

Input tokens are the tokens the application sends to the model. Output tokens are the tokens the model generates in response. The context window is the maximum number of tokens the model can consider at once. When the context window fills up, older or lower-priority information may drop out, or the request may fail depending on the system.
Input tokens can include system instructions, developer rules, the user’s prompt, chat history, retrieved documents, database snippets, tool schemas, tool results, and formatting examples. Output tokens include the final answer and, in some advanced systems, additional model-generated reasoning or tool-call content depending on the API design. OpenAI’s help documentation notes that usage metadata can include input, output, cached, and reasoning token categories.
Context windows are easy to misunderstand. A model with a long context window can accept more material, but teams still need to decide what belongs in that window. Sending every document, every previous chat turn, and every database field may increase cost and reduce focus. A retrieval-augmented generation system should send the most relevant evidence, not the largest possible bundle. Google’s Gemini long context documentation notes that newer models can handle very large context windows, but long context still works best when teams think carefully about what they include and how they retrieve it.
A practical context budget can divide the window into parts:
- Stable instructions: system rules, safety instructions, output schema, and tone guidance.
- Current user task: the latest question, file, image, or workflow request.
- Retrieved context: only the passages, records, or examples needed for the current task.
- Working memory: summaries, decisions, tool results, and important prior turns.
- Output reserve: enough room for the model to answer without being cut off.
This budgeting habit prevents teams from using the entire window for input and leaving too little space for a useful response.
Where Tokens Start To Matter For Developers And AI Teams
Tokens start to matter for developers and AI teams when AI features move from experimentation to repeated production use. Prompt design, chat memory, retrieval, summarization, agents, and document-heavy systems all need token controls.
Prompt design and prompt compression are the first area. Concise prompts reduce noise, but overly compressed prompts can remove critical constraints. A good prompt keeps the task, role, inputs, acceptance criteria, and output format while cutting repetition. Teams should measure whether shorter prompts preserve output quality before optimizing only for token count.
Chat history and memory management are the second area. Long conversations can become expensive and less focused if the application keeps every turn. A better design stores user preferences, task state, decisions, and summaries separately from raw history. Only relevant memory should return to the model.
Retrieval, summarization, and RAG workflows are the third area. A RAG system may retrieve dozens of passages but should usually send only the strongest evidence. Chunk size, ranking quality, deduplication, citations, and compression all affect token use. Designveloper’s RAG pipeline diagram guide frames this as a production workflow problem: the system must split documents, retrieve useful context, control cost, and make the answer verifiable.
Cost control in production apps, agents, and document-heavy systems is the fourth area. Teams should track tokens by feature and workflow type. An agent that calls a model ten times per task can spend more than a single chat answer. A document analysis workflow can spike usage when users upload long PDFs. A customer support assistant can grow costs when it sends entire ticket histories instead of targeted summaries.
Before launch, developers can use a compact production checklist to keep token usage from becoming a hidden reliability or budget problem.
- Budget each route: define expected input, output, cached input, and worst-case token ranges for every AI feature.
- Measure real usage: store response metadata so averages, p95 usage, and unusual spikes are visible by workflow.
- Control retrieval size: cap retrieved chunks, deduplicate passages, and prefer smaller source excerpts with strong relevance.
- Separate memory from transcript: store summaries, decisions, user preferences, and structured task state instead of replaying every message.
- Reserve output room: leave enough tokens for the answer, citations, JSON fields, or tool-call result the task requires.
- Review agent steps: track token use per planning step, tool call, retry, and final response so loops do not hide cost.
For agentic workflows, token planning also overlaps with safety. Designveloper’s agentic AI security guide explains why tool permissions, auditability, and guardrails matter when an AI system can take actions across multiple steps.
A useful developer checklist looks like this:
- Count tokens before sending large prompts, documents, or tool schemas.
- Reserve output space instead of filling the whole context with input.
- Summarize or retrieve older history instead of sending every prior turn.
- Trim unused JSON fields, duplicate passages, logs, and code comments.
- Monitor actual token usage from response metadata, not only estimates.
- Set feature-level limits for agents, document analysis, and long chats.
Common Misunderstandings About Tokens In AI

Common misunderstandings about tokens usually come from treating tokens as words, treating context windows as memory, or treating larger context as automatically better. These assumptions lead to cost surprises and weaker AI performance.
The first misunderstanding is that one token equals one word. Tokens are model-specific pieces. A long technical identifier, code expression, or multilingual phrase may use more tokens than expected. Word count can support rough estimates, but real applications should use token counting tools.
The second misunderstanding is that context windows are permanent memory. A context window is the active material available for one model call or conversation state. Durable memory usually requires application design: stored summaries, user profiles, retrieval indexes, databases, and explicit state management.
The third misunderstanding is that bigger context always improves performance. Long context can help when the relevant evidence is buried in a large document set. It can hurt when the prompt includes noisy, conflicting, stale, or duplicated information. Google’s Gemini long context documentation recommends thinking carefully about what long context can achieve and how to optimize its use.
The fourth misunderstanding is that token optimization means making prompts as short as possible. The better goal is useful density. Remove repeated boilerplate, but keep constraints, examples, definitions, and acceptance criteria that improve output quality. A cheap wrong answer is still expensive when a human must repair it.
The fifth misunderstanding is that token costs are only a developer concern. Product managers, support leaders, and operations teams should understand token drivers because token use maps to feature economics. A high-volume customer service workflow, long-chat assistant, or document automation feature needs a cost model before launch.
Better Token Decisions Lead To Better AI Performance
Better token decisions lead to better AI performance because they keep the model focused on useful context, reduce avoidable cost, improve latency, and preserve important information across long workflows. Token management should be treated as part of AI product design.
Keep prompts concise without removing useful context. Good prompts state the task, inputs, constraints, examples, and expected output. Weak prompts include repeated policy text, irrelevant history, vague instructions, or large document excerpts with no ranking. The goal is not minimal text. The goal is high signal per token.
Reduce unnecessary history with summarization or retrieval. Long chats should not pass every turn forever. Summaries can preserve decisions, preferences, and open tasks. Retrieval can bring back only the most relevant records. Agents can store structured state instead of raw transcripts.
Watch token-heavy workflows such as long chats, agents, and document analysis. These workflows often grow gradually until cost, latency, or quality becomes visible to users. Monitor average, p95, and worst-case token usage. Set alerts when token use spikes after new features, prompt changes, or tool additions.
Choose model and context settings based on real cost, speed, and output needs. A model with a huge context window may be valuable for complex document review, but overkill for short classification. A smaller model may handle extraction or routing well. A stronger model may be justified for complex reasoning or high-risk customer responses. Token metrics help teams make those tradeoffs with evidence.
Designveloper helps teams make these tradeoffs when building AI products and automation workflows. Our AI development services connect model selection, RAG design, prompt architecture, observability, and human review with real product constraints. Our delivery process then carries those decisions through discovery, engineering, testing, deployment, and support. Token planning is one of those constraints because token use affects architecture, UX, cost, and reliability long after the first prototype works.
FAQs About Tokens In AI
The following answers summarize the token questions developers, product teams, and business stakeholders usually ask before building AI features.
Is A Token The Same As A Word In AI?
No. A token is not the same as a word in AI. A token can be a word, part of a word, punctuation mark, symbol, space pattern, number, or code fragment. Tokenizers differ across model providers, so the same sentence can produce different token counts in different models.
Why Do AI Tools Charge By Tokens?
AI tools charge by tokens because tokens measure how much input the model processes and how much output the model generates. Token billing gives providers a usage-based way to price computation. It also gives developers a measurable unit for cost controls, quotas, and feature economics.
What Is The Difference Between Input And Output Tokens?
Input tokens are the tokens sent to the model, including prompts, instructions, chat history, retrieved context, and tool-related information. Output tokens are the tokens the model generates in response. Both categories can affect cost, latency, and context budgeting.
How Do Tokens Affect Context Window Limits?
Tokens affect context window limits because each model can consider only a maximum number of tokens at once. If the combined request, context, and expected output exceed that limit, the application must shorten, summarize, retrieve more selectively, or choose a model with a larger context window.
Why Do Token Counts Change Across AI Models?
Token counts change across AI models because tokenizers, vocabularies, and supported modalities differ. A model trained with one tokenizer may split text differently from another model. Developers should use the provider’s token counting tool when exact counts matter for cost, limits, or routing.
Tokens are the hidden measurement layer behind AI context and performance. Teams that understand tokens can write better prompts, design cleaner RAG systems, control production costs, and build AI workflows that stay coherent as they scale.
Also published on

Share post on










Related Articles

What Are AI Tokens? How Tokens Shape Context And AI Performance
What Are AI Tokens? How Tokens Shape Context And AI Performance Published June 18, 2026
What Are AI Hallucinations? How To Reduce The Risk
What Are AI Hallucinations? How To Reduce The Risk Published June 18, 2026
LangGraph Vs MCP: How They Work Together In Advanced AI Systems
LangGraph Vs MCP: How They Work Together In Advanced AI Systems Published June 18, 2026





















