












What Is Deep Learning? How It Helps AI Learn From Data
KEY TAKEWAYS:
- Deep learning is a branch of machine learning that uses layered neural networks to learn patterns from complex data such as images, speech, text, video, and behavior logs.
- Modern AI depends heavily on deep learning because neural networks power large language models, computer vision, speech AI, generative AI, recommendation systems, and many automation workflows.
- Deep learning needs more than a model: teams still need clean data, evaluation, human review, secure integration, monitoring, and clear business metrics.
- Different model families solve different problems, from CNNs for images and transformers for language to diffusion models for generation and GNNs for relationship-heavy data.
- Businesses should start from a workflow, then decide whether to use APIs, pre-trained models, fine-tuning, custom training, retrieval, or human feedback to build a reliable AI system.
Deep learning sits behind many AI systems people now use every day. It helps software read images, understand speech, translate text, recommend products, detect fraud, and generate new content. The simple answer to “what is deep learning” is this: deep learning is a branch of machine learning that uses layered neural networks to learn patterns from data.
This matters because AI has moved from research labs into real business workflows. Stanford’s 2025 AI Index reports that 78% of organizations reported using AI in 2024. McKinsey’s 2025 global survey also shows that 23% of respondents report their organizations are scaling an agentic AI system somewhere in their enterprises. Many of these systems rely on deep learning models, directly or indirectly.
This guide explains deep learning in simple terms. It covers how deep neural networks work, how they learn from data, which model types matter, how machine learning vs deep learning differs, and how companies can build useful systems without turning AI into a black box.
Recommended for you:
- AI Tools For Developers: Best Tools To Improve Developer Workflow
- AI In Product Development: How Teams Use AI To Build Better Products
- AI MVP To Product: How To Turn An AI Prototype Into A Real Product
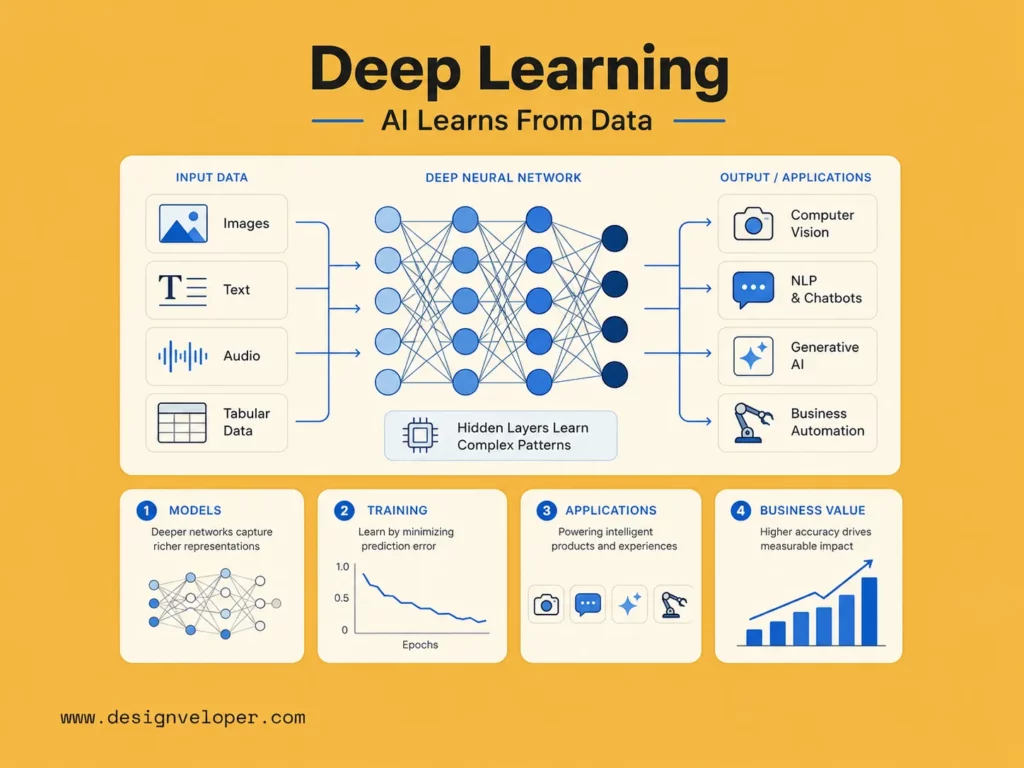
What Is Deep Learning?
1. Deep Learning Explained in Simple Terms
Deep learning is a type of machine learning. It uses artificial neural networks with many layers. These layers help a model turn raw data into useful predictions, decisions, or generated outputs.
IBM defines deep learning as a subset of machine learning driven by multilayered neural networks. That definition is important because it separates deep learning from normal rule-based software. A normal program follows fixed instructions. A deep learning model learns useful patterns from examples.
Think about image recognition. A normal program may need a developer to write rules for edges, shapes, colors, and object parts. A deep learning model can learn many of those patterns from labeled images. Early layers may detect simple lines. Middle layers may detect textures or parts. Later layers may detect full objects.
That is why deep learning works well with complex data. Images, audio, video, text, medical scans, sensor logs, and user behavior all contain patterns that can be hard to describe by hand. Deep learning can learn those patterns through training.
So, when people ask what is deep learning, the most useful answer is not “AI that copies the brain.” A better answer is this: deep learning is a data-driven method that uses layered neural networks to learn features and make predictions from complex data.
2. Why Deep Learning Is a Core Part of Modern AI
Deep learning became central to modern AI because it handles scale and complexity better than many older methods. Traditional machine learning still works well for structured data. However, deep learning often performs better when the input is messy, rich, and high-dimensional.
For example, a sales table may have columns like deal size, region, and close date. A classic machine learning model can handle that well. However, a support call recording, a product image, or a long contract has far more hidden structure. Deep learning can process this kind of unstructured data more naturally.
Deep learning also powers many generative AI systems. Large language models, image generators, speech models, and multimodal assistants all depend on neural networks. OpenAI describes GPT-4 as a Transformer-style model pre-trained to predict the next token in a document. That training pattern is a deep learning approach.
However, deep learning is not magic. It still needs clear goals, enough data, careful evaluation, and strong human review. The model learns from examples. Therefore, weak data creates weak results. Poor labels create poor predictions. Bad evaluation creates false confidence.
That is the practical point. Deep learning helps AI learn from data, but people still define the problem, prepare the data, test the model, and decide how the system should fit real workflows.
Further reading:
- AI Engineer Vs ML Engineer: Key Differences, Skills, And Responsibilities
- AI Programming Language: Best Languages For Building AI Systems
- AI With Python: How Python Powers Modern AI Development
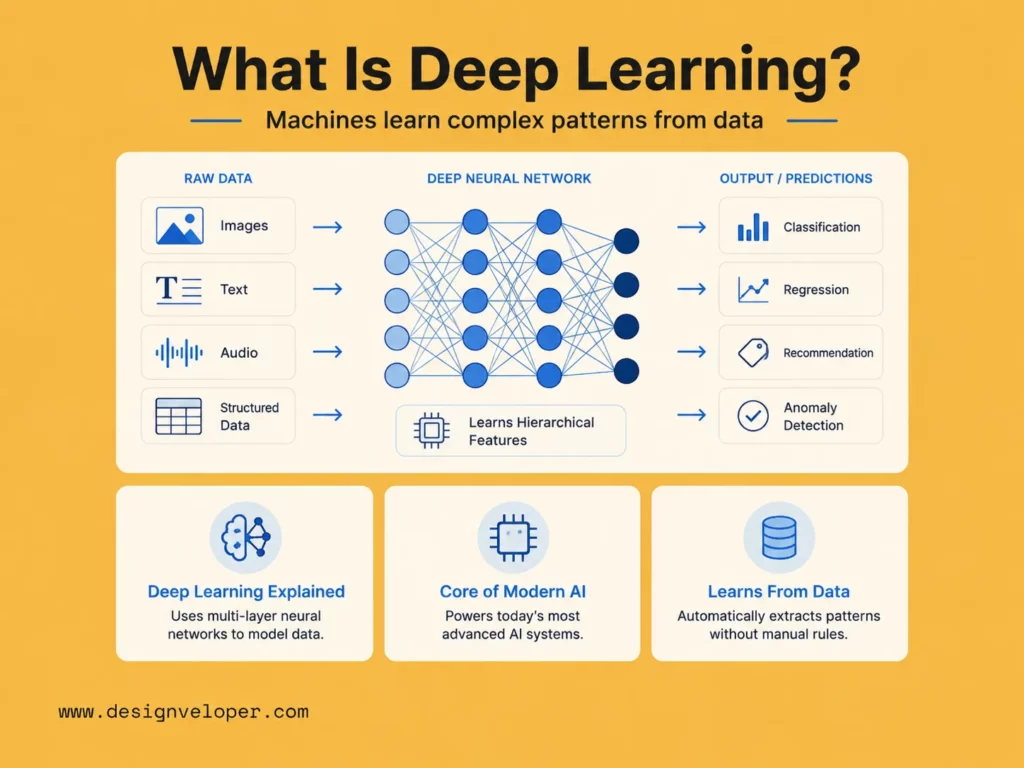
How Deep Learning Works
1. Deep Neural Network Structure
A deep neural network has layers. Each layer transforms data in small steps. The first layer receives input. Hidden layers process the input. The final layer produces an output.
For example, an image model may receive pixels as input. The first layers may learn edges. Deeper layers may learn object parts. The output layer may predict “cat,” “invoice,” “tumor,” or another class. The model does not start with these patterns. It learns them during training.
Most deep neural networks include these parts:
| Part | What It Does | Simple Example |
|---|---|---|
| Input layer | Receives raw data or prepared features | Pixels, words, audio samples, or transaction fields |
| Hidden layers | Find patterns through learned weights | Edges in images or meaning in sentences |
| Activation function | Adds non-linear behavior | Helps the model learn complex patterns |
| Output layer | Returns a prediction or generated result | A class, score, word, image, or recommendation |
The word “deep” refers to the number of layers. More layers can help a network learn more abstract patterns. However, more layers also add cost and complexity. A deeper model is not always better. The best model depends on the task, the data, and the business requirement.
2. How Deep Learning Models Learn From Data
Deep learning models learn by adjusting internal values called weights. At first, these weights do not know the task. The model makes weak predictions. Then it compares its output with the correct answer. After that, it updates the weights to reduce the error.
This process repeats many times. Each pass helps the model improve. Over time, the network learns which patterns matter and which ones do not.
A simple training loop looks like this:
- The model receives training data.
- It makes a prediction.
- The system calculates the error.
- The model updates its weights.
- The process repeats until performance improves.
For a fraud detection model, the input may include transaction amount, device signal, location, and merchant behavior. The output may be a fraud risk score. For a language model, the input may be text tokens. The output may be the next likely token.
The same idea applies across many domains. Deep learning turns examples into learned patterns. Then it uses those patterns on new data.
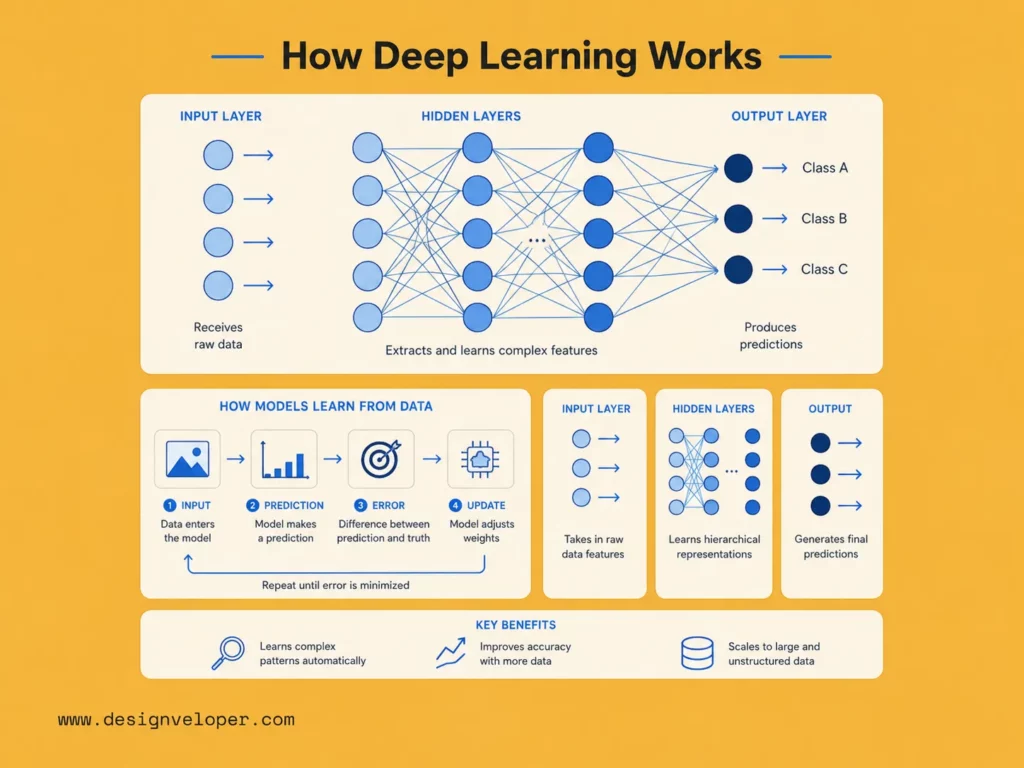
Training Deep Neural Networks
1. Backpropagation
Backpropagation is the method that tells the model how each weight affected the error. It works backward from the output layer to earlier layers. Then it calculates how much each part of the network should change.
This matters because a deep network may have millions or billions of weights. A developer cannot tune them by hand. Backpropagation gives the training system a way to improve the network step by step.
Here is the basic idea. The model makes a prediction. The system measures the loss. The loss shows how wrong the model was. Backpropagation then spreads that error signal back through the network. Each layer receives feedback. Then the optimizer updates the weights.
Backpropagation does not make a model intelligent by itself. It only gives the model a way to learn from error. The quality of the result still depends on the data, model design, training setup, and evaluation process.
2. Gradient Descent
Gradient descent is the method that moves the model toward lower error. It looks at the direction of the error and adjusts weights in a better direction. The model does this again and again during training.
A useful analogy is walking downhill in fog. You cannot see the whole landscape. However, you can feel which direction slopes down from your current position. Gradient descent does the same thing with model error.
The learning rate controls how large each step is. If the learning rate is too high, the model may jump past a good solution. If it is too low, training may take too long. This is why training deep neural networks involves many engineering choices.
Teams also use variations of gradient descent. Some methods update weights after a small batch of examples. Others adjust the step size during training. These choices can affect speed, stability, and final accuracy.
3. Why Deep Learning Needs Large Datasets and GPUs
Deep learning often needs large datasets because it learns patterns from examples. More diverse examples help the model generalize. If the model sees only narrow data, it may fail on real-world inputs.
Computer vision shows this clearly. ImageNet says its project has been instrumental in advancing computer vision and deep learning research. Large image datasets helped researchers train models that could recognize objects more accurately. Speech AI follows a similar pattern. Mozilla’s Common Voice release reached 32,584 hours of open speech data, which shows how much audio data modern speech systems may need.
Deep learning also needs strong computing power. Neural networks perform many matrix operations. GPUs handle many of these operations in parallel. NVIDIA describes CUDA as the software layer that enables applications to harness the power of GPUs. This is why deep learning teams often use GPUs for training and sometimes for inference.
However, not every company needs to train a huge model from scratch. Many teams use pre-trained models. Then they fine-tune them, connect them to private data, or use them through APIs. This reduces cost and speeds up delivery.
Related reading:
- AI Hallucinations: Causes, Risks, And How To Reduce Them
- RAG Vs Fine Tuning: How To Choose The Right AI Approach
- RAG Best Practices: How To Improve Retrieval-Augmented Generation
Common Types of Deep Learning Models
1. Convolutional Neural Networks (CNNs)
Convolutional Neural Networks, or CNNs, work well with images and spatial data. They scan input with filters. These filters learn local patterns such as edges, corners, textures, and shapes.
CNNs became important because images contain spatial structure. A pixel has meaning based on nearby pixels. CNNs preserve that structure better than a simple fully connected network.
Common CNN use cases include medical image analysis, defect detection, face recognition, satellite image classification, and document layout analysis. A factory may use a CNN to detect scratches on a product line. A logistics company may use one to read package images. A healthcare team may use one to highlight suspicious scan regions for review.
CNNs are still useful. However, transformers and hybrid models now compete with them in many vision tasks. The right choice depends on data size, latency, cost, and accuracy needs.
2. Recurrent Neural Networks (RNNs)
Recurrent Neural Networks, or RNNs, process sequences. They were designed to handle data where order matters. Text, speech, time series, and sensor streams all fit this pattern.
An RNN reads input step by step. It keeps a memory of earlier steps. That memory helps the model understand the current step in context.
For example, the word “bank” can mean a financial institution or the side of a river. The surrounding words help define the meaning. RNNs helped early natural language systems use this context.
Still, RNNs struggle with long sequences. They can lose earlier context as the input grows. This is one reason transformers became more popular for language tasks. RNNs still appear in some time-series, embedded, or lightweight systems, but they no longer dominate modern NLP.
3. Autoencoders
Autoencoders learn to compress data and rebuild it. They have two main parts. The encoder reduces the input into a smaller representation. The decoder tries to reconstruct the original input.
This structure helps the model learn useful hidden patterns. If it can rebuild the input from a smaller representation, it has learned something important about the data.
Autoencoders can support anomaly detection, noise removal, compression, and feature learning. For example, a bank may train an autoencoder on normal transaction behavior. When a new transaction looks hard to reconstruct, the system may flag it as unusual.
Autoencoders are also useful when labeled data is limited. They can learn structure from unlabeled data. Then teams can use the learned representation for other tasks.
4. Transformer Models
Transformer models changed deep learning for language, code, search, and generative AI. They use attention to decide which parts of the input matter most. The original Transformer paper proposed a model based solely on attention mechanisms.
Attention helps a model compare words, tokens, or image patches with one another. This allows the model to capture long-range relationships. It also supports more parallel training than older sequence models.
Transformers power many large language models. They also support translation, summarization, question answering, code generation, search ranking, document analysis, and multimodal AI.
Businesses often meet transformers through tools such as ChatGPT, enterprise copilots, document assistants, and AI search systems. These systems can summarize reports, answer policy questions, extract contract terms, or generate support replies. However, they still need guardrails, retrieval, evaluation, and human review.
5. Generative Adversarial Networks (GANs)
Generative Adversarial Networks, or GANs, use two models. One model generates data. The other model judges whether the output looks real. The original GAN paper describes an adversarial process in which two models train against each other.
This setup can produce realistic images, enhance photos, create synthetic data, and support style transfer. The generator improves because the discriminator keeps challenging it. The discriminator improves because the generator keeps producing harder examples.
GANs helped push image generation forward. However, they can be hard to train. They may also suffer from unstable behavior or limited output variety. Diffusion models now lead many image generation workflows, but GANs still matter in research and some production tasks.
6. Diffusion Models
Diffusion models generate data by learning how to remove noise. During training, the system adds noise to real data. Then the model learns to reverse that process. During generation, it starts from noise and gradually creates a useful output.
The Denoising Diffusion Probabilistic Models paper presents diffusion probabilistic models for high-quality image synthesis. This idea now sits behind many modern image generation systems.
Diffusion models are strong for image generation, image editing, design exploration, and creative workflows. They can produce high-quality outputs. They also give teams more control through prompts, masks, conditioning, and guidance methods.
However, they can require more compute than some other model types. They also need content safety checks when used in public products. A business should treat them as creative engines, not as automatic truth machines.
7. Graph Neural Networks
Graph Neural Networks, or GNNs, process data that has entities and relationships. IBM explains that GNNs represent data about entities and their relationships. This makes them useful when the relationship between items matters as much as the items themselves.
Examples include social networks, fraud rings, supply chains, molecules, recommendation systems, and knowledge graphs. A normal table may miss these connections. A graph can show them directly.
For example, a fraud model may look at users, devices, bank accounts, phone numbers, and transactions as connected nodes. A GNN can learn suspicious patterns across that network. This helps teams detect coordinated behavior that may not appear in one record alone.
GNNs can add value when data has rich relationships. However, they need careful graph design. The team must define nodes, edges, features, and update rules in a way that matches the real problem.
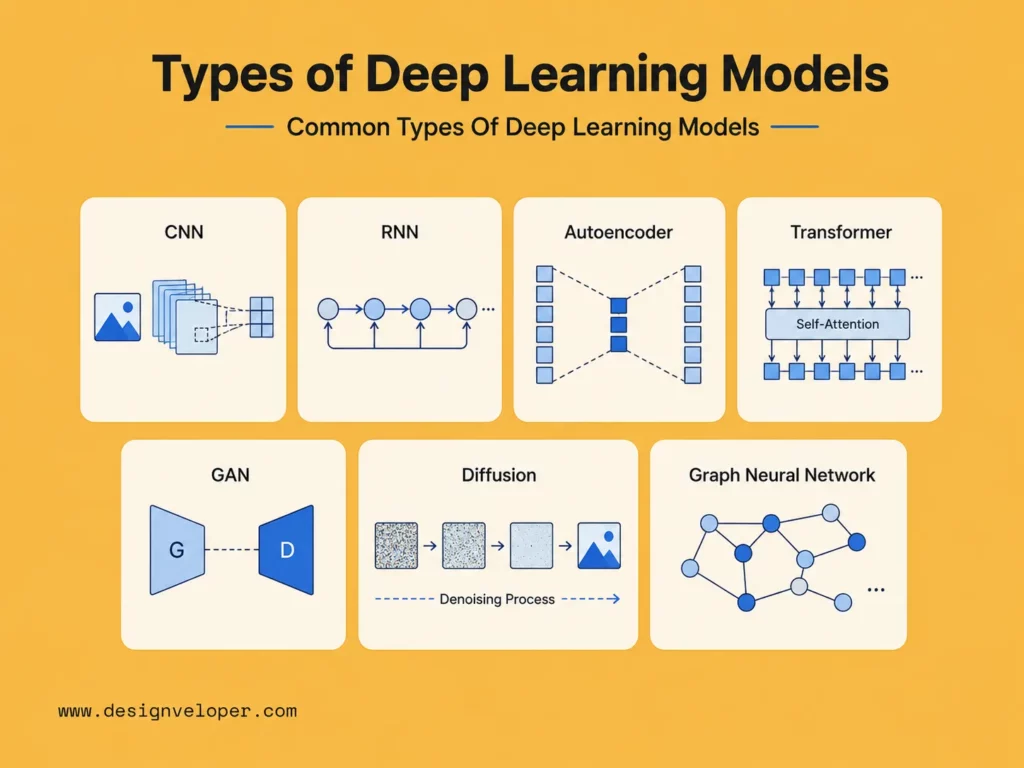
Deep Learning vs Machine Learning
1. Manual Feature Engineering vs Automatic Feature Learning
The main difference between machine learning vs deep learning is how each method handles features. Traditional machine learning often needs humans to define features. Deep learning can learn many features from raw or lightly processed data.
For example, a traditional fraud model may use features such as transaction amount, country risk, device age, and past chargebacks. Analysts design these inputs. The model then learns from them.
A deep learning model may learn more complex patterns from raw sequences, text, images, or behavior logs. It can discover patterns that humans may not define by hand. This is useful when the data contains many hidden signals.
| Area | Traditional Machine Learning | Deep Learning |
|---|---|---|
| Feature work | Humans often design features | The model learns many features |
| Best data fit | Structured tables and smaller datasets | Images, audio, text, video, and large datasets |
| Compute needs | Often lower | Often higher |
| Explainability | Often easier to inspect | Often harder to explain |
| Typical use | Forecasting, scoring, segmentation | Vision, speech, NLP, generative AI |
This does not mean deep learning replaces machine learning. Both matter. A company may use classic ML for churn prediction and deep learning for document understanding. The best AI system often combines several methods.
2. When Deep Learning Performs Better Than Traditional Machine Learning
Deep learning performs better when data has complex patterns that humans cannot easily define. This often includes images, long text, speech, video, code, and high-volume behavior signals.
It also performs better when the business has enough data and a clear evaluation method. A deep model may look powerful in a demo but fail if the training data does not match real users. Therefore, the question is not only whether deep learning can work. The better question is whether the business has the right data, workflow, and review process.
Deep learning may be a good fit when:
- The data is unstructured or semi-structured.
- The task needs pattern recognition at scale.
- Manual rules break too often.
- The company has enough examples for training or fine-tuning.
- The output can be tested with clear metrics.
- The workflow can include human review for high-risk decisions.
Traditional machine learning may still be better when the dataset is small, the task is simple, or the business needs high explainability. For example, a pricing model in a regulated setting may need a clear reason for each score. In that case, a simpler model may be safer and easier to govern.
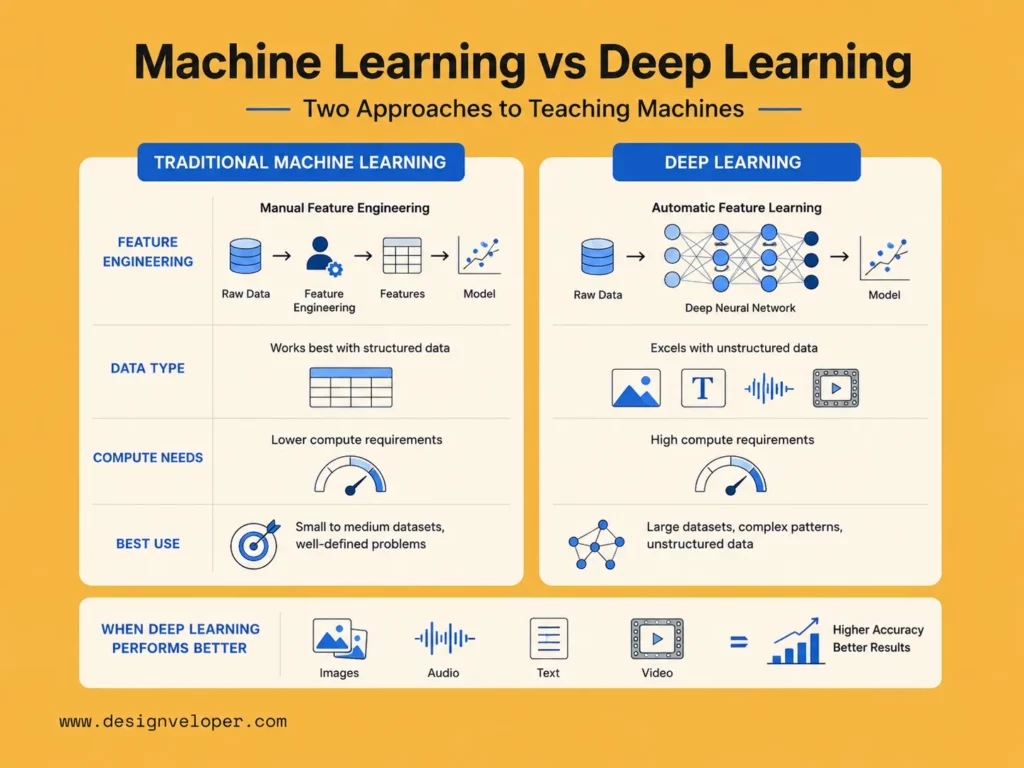
Real-World Applications of Deep Learning
1. Computer Vision
Computer vision helps software understand images and video. Deep learning made this field more useful because vision tasks depend on complex visual patterns.
Companies use computer vision for quality control, retail analytics, medical image support, safety monitoring, identity checks, and document capture. A manufacturer can detect defects on a production line. A logistics team can read labels from package photos. A hospital can use AI to support scan review, while doctors keep final responsibility.
Computer vision also helps document workflows. A model can detect tables, signatures, stamps, line items, and layout zones. Then another system can extract fields and send them into a business workflow. This matters for finance, insurance, legal, HR, and back-office teams.
The key is workflow fit. A vision model should not just return a label. It should help a person or system act faster, with clear confidence scores and review paths.
2. Natural Language Processing and Speech AI
Natural Language Processing, or NLP, helps software understand and generate language. Speech AI helps software turn audio into text, text into speech, or spoken input into action.
Deep learning supports translation, summarization, sentiment analysis, search, chatbots, call transcription, voice assistants, and meeting summaries. Google Cloud says Speech-to-Text can convert audio into text transcriptions and integrate speech recognition into applications. This kind of capability becomes more useful when connected to business systems.
For example, a call center can transcribe calls, summarize issues, detect follow-up tasks, and push notes into a CRM. An HR team can use a policy assistant to answer employee questions. A legal team can search long agreements and extract key clauses.
However, language and speech systems need strong controls. They can misunderstand context. They can produce confident but wrong answers. They can also expose sensitive data if the workflow lacks access control. Good systems include retrieval, permissions, logging, and human review.
3. Generative AI
Generative AI creates new content. It can produce text, images, code, audio, summaries, product descriptions, emails, and design drafts. Deep learning powers most modern generative AI systems.
The business value is clear. Generative AI can reduce drafting time, support customer service, speed up research, and help teams explore ideas. Stack Overflow’s 2025 Developer Survey says 84% of respondents are using or planning to use AI tools in their development process. This shows how fast AI-assisted work has moved into software teams.
Still, generative AI needs verification. A generated answer may sound fluent and still be wrong. A generated code snippet may work for one case and fail in production. A generated image may create legal or brand issues. Therefore, teams should use generative AI as a productivity layer, not as an unchecked authority.
Good use cases start with narrow workflows. Examples include support response drafts, contract summaries, internal knowledge search, product copy variants, and code review assistance. These use cases let teams measure quality before expanding.
Continue reading:
- AI Apps: Best Tools And How To Choose The Right AI App For Your Workflow
- AI Business Process Automation: Benefits, Use Cases, And How To Start
- Using AI In Software Development: Practical Benefits, Risks, And Use Cases
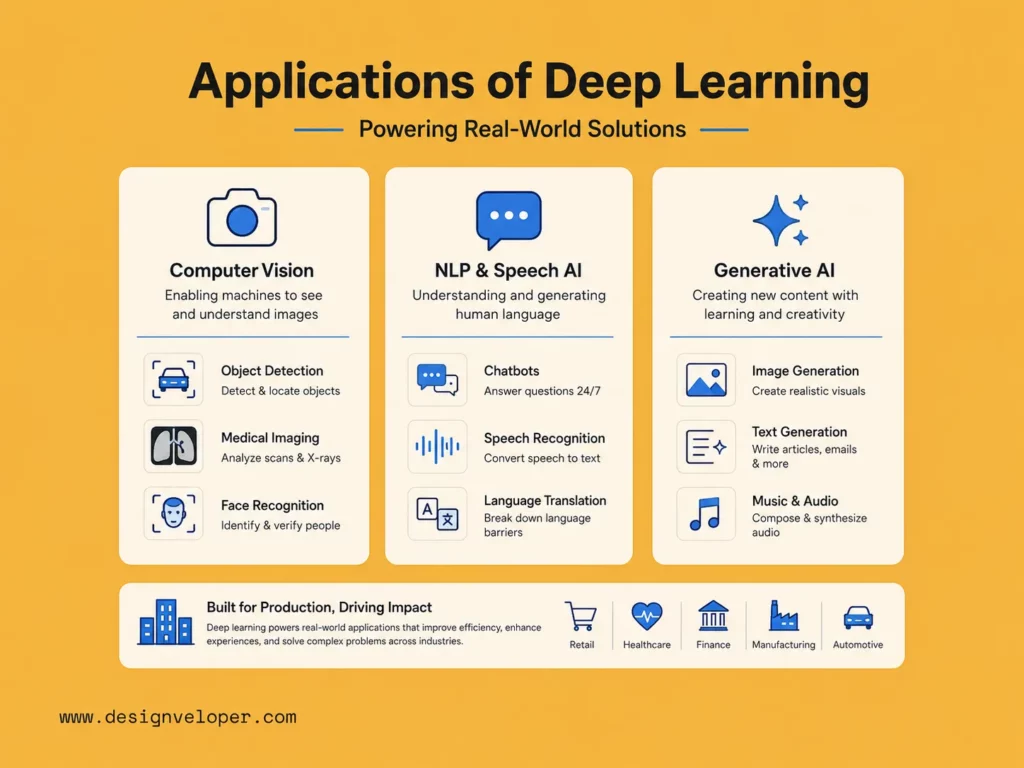
Why Deep Learning Matters for Businesses
1. Better Pattern Recognition on Unstructured Data
Most business data does not live in clean tables. It lives in PDFs, emails, chat logs, images, call recordings, scanned forms, tickets, and product photos. Deep learning helps companies use this data instead of leaving it outside analytics systems.
This matters because unstructured data often contains important signals. A customer complaint may reveal churn risk. A contract clause may reveal revenue exposure. A receipt image may contain expense data. A support call may reveal product friction.
Deep learning can turn these signals into searchable, classifiable, and actionable information. It can extract entities, classify documents, detect patterns, and route work. This gives teams faster access to information that once required manual review.
The business result is not just “better AI.” The result is better workflow speed, fewer manual checks, and more consistent handling of repeated tasks.
2. Higher Automation Potential
Deep learning increases automation potential because it handles tasks that simple rules cannot cover. A rules engine works well when conditions are clear. However, many business inputs are messy. Customers phrase requests in different ways. Documents vary by format. Images change by lighting and angle. Calls include accents, pauses, and background noise.
Deep learning can handle more variation. It can classify requests, extract fields, summarize conversations, predict risk, or recommend next actions. Then workflow automation can move the task forward.
For example, an invoice workflow may use deep learning to read the invoice, match it to a purchase order, detect missing fields, and send exceptions to a reviewer. A support workflow may classify a ticket, generate a suggested reply, and route the case to the right team.
The best automation does not remove humans from every step. It removes repetitive work and keeps people in control of exceptions, approvals, and high-impact decisions.
3. More Scalable AI Applications
Deep learning helps companies build AI applications that scale across many inputs. Once a model works well, it can process far more data than a manual team can handle alone.
This is useful for product teams and operational teams. A SaaS product can add AI search across user documents. A finance team can process more invoices without hiring at the same rate. A customer service team can summarize more conversations and spot trends faster.
Scalable AI also needs scalable engineering. The team must manage data pipelines, model serving, monitoring, feedback, security, and cost. A model that performs well in a notebook may fail under production traffic. This is why deep learning projects need both AI knowledge and software engineering discipline.
Business teams should measure scalability through practical metrics. These may include processing time, review rate, error rate, cost per task, user satisfaction, and human override frequency. These metrics show whether the system improves real work.
How Companies Build and Use Deep Learning Systems
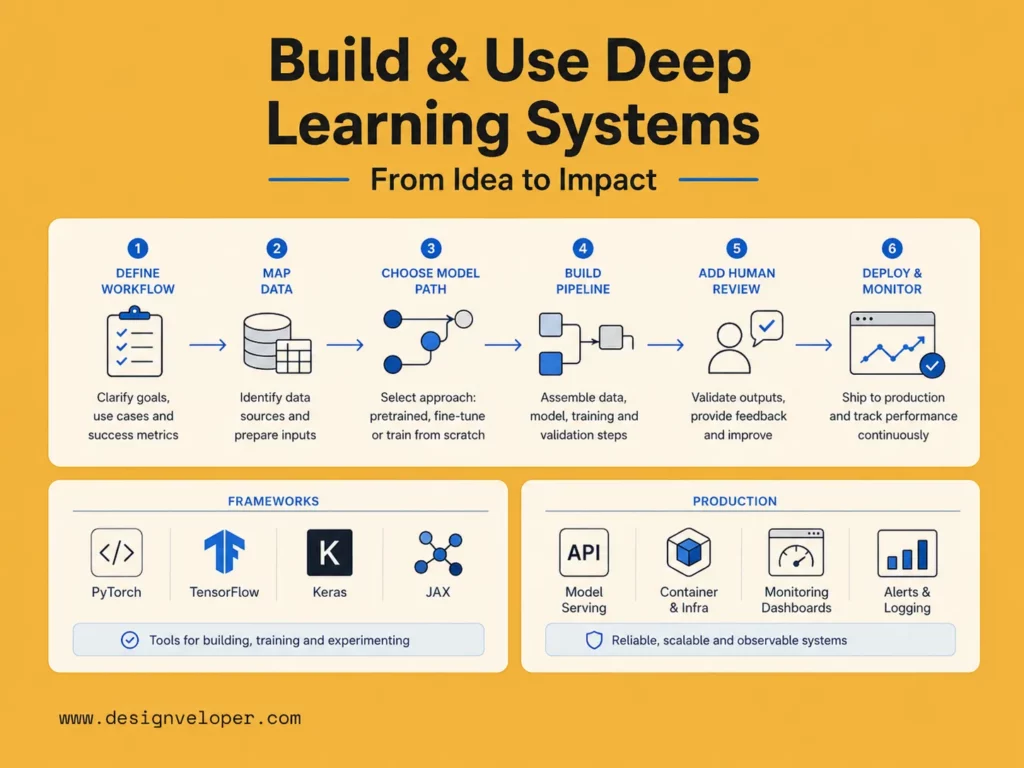
Companies should build deep learning systems around real workflows, not around model hype. The process starts with a business problem. Then the team checks whether deep learning is the right method.
A strong build path usually follows this sequence:
| Step | What the Team Does | Why It Matters |
|---|---|---|
| Define the workflow | Choose one process, task, or user problem | Prevents vague AI experiments |
| Map the data | Check sources, quality, access, labels, and privacy | Shows whether the model can learn safely |
| Choose the model path | Use an API, fine-tune a model, or train a custom model | Controls cost and delivery speed |
| Build the pipeline | Prepare data, train or connect the model, and test outputs | Turns research into a working system |
| Add human review | Set confidence thresholds, approvals, and exception handling | Reduces risk in real decisions |
| Deploy and monitor | Track accuracy, drift, cost, latency, and user feedback | Keeps the system useful after launch |
Teams also need the right deep learning frameworks. PyTorch describes itself as an optimized tensor library for deep learning using GPUs and CPUs. TensorFlow positions Keras as the high-level API of the TensorFlow platform. JAX supports accelerator-oriented array computation for high-performance machine learning. Hugging Face Transformers provides everything needed for inference or training with state-of-the-art pretrained models. ONNX gives teams an open format built to represent machine learning models.
These tools solve different problems. PyTorch is common for research and flexible model development. TensorFlow and Keras remain useful for production ML workflows and fast experimentation. JAX fits high-performance research and large-scale training. Hugging Face helps teams use pretrained transformer models faster. ONNX helps move models across tools and runtimes.
However, frameworks do not guarantee value. A company also needs product thinking. The model must sit inside a useful interface. The output must trigger the next action. The system must respect access rules. Users must know when to trust the model and when to review it.
For many companies, the best path is not to train a deep model from zero. It is to start with a narrow workflow and use existing models where possible. Then the team can add retrieval, fine-tuning, custom classification, or human feedback as the system matures.
At Designveloper, we approache this kind of work as a software and workflow problem, not only as a model problem. A deep learning system may need document parsing, AI assistants, HR automation, dashboards, data pipelines, API integrations, security controls, and production monitoring. The useful outcome is a system that helps a team work faster and with fewer manual steps.
For a deeper dive, read:
- AI Software Development: How Teams Use AI Across The SDLC
- RAG Pipeline Diagram: How Retrieval-Augmented Generation Works
- Custom Software Development: Benefits, Process, And Cost Factors
FAQs About Deep Learning
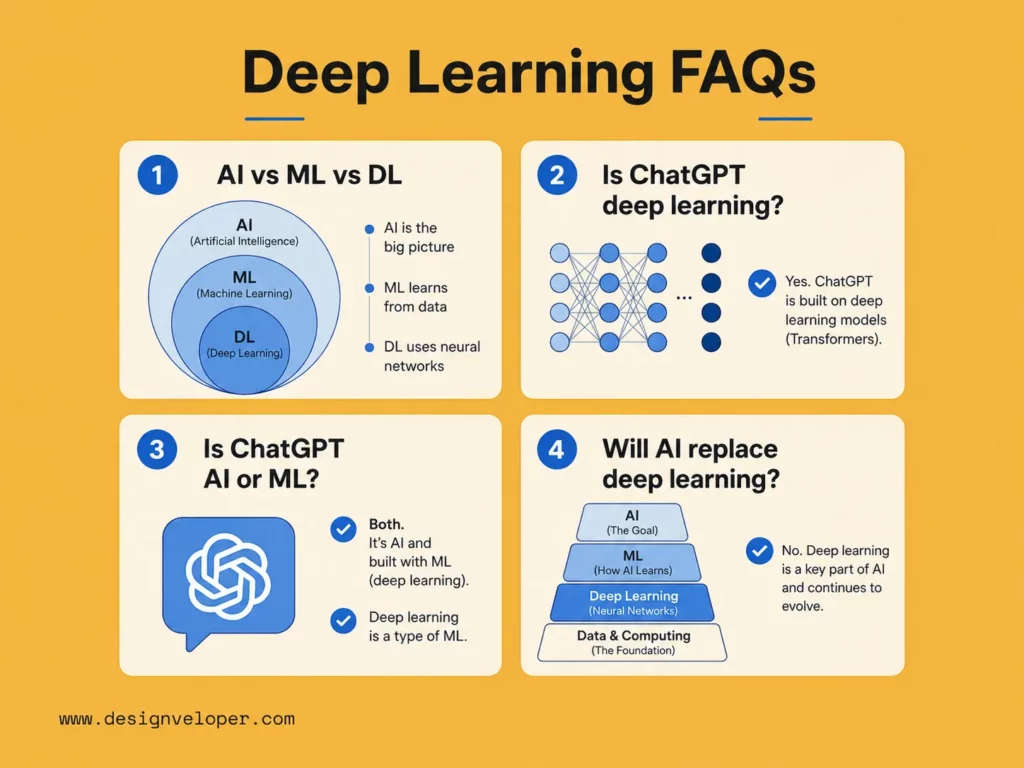
1. What Is AI vs ML vs DL?
AI is the broad field of making machines perform tasks that need human-like intelligence. Machine learning is a part of AI that lets systems learn patterns from data. Deep learning is a part of machine learning that uses multilayered neural networks.
So, ai machine learning and deep learning form a nested relationship. AI is the largest category. Machine learning sits inside AI. Deep learning sits inside machine learning.
A simple example helps. A rule-based chatbot can be AI without machine learning. A churn prediction model can be machine learning without deep learning. A transformer-based language model is deep learning.
2. Is ChatGPT Deep Learning?
Yes. ChatGPT relies on deep learning. OpenAI explains that ChatGPT is designed to respond by learning patterns from large amounts of information, including text, images, audio, and video. That pattern learning depends on neural network models.
More specifically, ChatGPT belongs to the large language model family. These models use transformer-based deep learning to process prompts and generate responses. However, ChatGPT is not only a raw model. It is also a product with safety systems, interfaces, tools, policies, and deployment choices around the model.
3. Is ChatGPT AI or ML?
ChatGPT is AI, and it uses machine learning. More precisely, it uses deep learning, which is a subfield of machine learning.
This distinction matters because “AI” describes the broad capability. “Machine learning” describes the data-driven method. “Deep learning” describes the neural network approach that powers many modern language models.
So, the best answer is simple. ChatGPT is an AI system built with machine learning methods, especially deep learning.
4. Will AI Replace Deep Learning?
No. AI will not replace deep learning in a simple sense because deep learning is one of the main methods used to build AI. Future AI systems may combine deep learning with symbolic reasoning, search, memory, retrieval, planning, simulation, and traditional software. However, deep learning will likely remain a core layer for perception, language, generation, and pattern recognition.
The better question is whether every AI task needs deep learning. The answer is no. Some tasks work better with rules, search, classic machine learning, optimization, or simple automation. Strong teams choose the method that fits the workflow.
Conclusion: Deep learning helps AI learn from data by using layered neural networks. It works best when data is complex, large, and hard to describe with manual rules. That is why deep learning models now support computer vision, speech AI, natural language processing, generative AI, fraud detection, recommendation systems, and document automation.
Still, deep learning creates value only when teams connect it to real work. The model needs clean data, clear metrics, human review, secure integration, and ongoing monitoring. For businesses, the goal is not to use the deepest model. The goal is to build an AI system that improves a real workflow, scales safely, and helps people make better decisions.
Conclusion
Deep learning is more than a technical concept. It is one of the core methods that helps AI learn from data, recognize complex patterns, and power real applications in computer vision, NLP, speech AI, generative AI, automation, and intelligent software systems.
For businesses, the real value does not come from choosing the largest model. It comes from choosing the right workflow, preparing the right data, testing the output, and connecting the model to a product or operation that people actually use.
At Designveloper, we approach deep learning as part of a broader AI-first software strategy. Since our founding in early 2013 in Ho Chi Minh City, Vietnam, we have delivered 100+ projects across 20+ industries and applied 50 technologies across real product environments. Our work spans AI-powered business software, custom software development, web app development, mobile app development, UI/UX design, and VoIP app development.
That experience shapes how we build AI systems. A deep learning model may need document parsing, model integration, data pipelines, dashboards, human review, security controls, and production monitoring. We have seen this in projects such as Lumin, where document workflows require reliable PDF viewing, editing, sharing, and signing, and in AI-focused work such as Song Nhi, where intelligent assistance supports personal finance tasks.
So, the next step is not just to ask whether deep learning can solve a problem. The better question is which business workflow should become faster, smarter, or more scalable. Designveloper can help teams answer that question, design the right AI architecture, and turn deep learning ideas into production-ready software.
Also published on

Share post on










Related Articles

AI Chatbot Development: A Step-By-Step Guide
AI Chatbot Development: A Step-By-Step Guide Published July 15, 2026
Claude Vs ChatGPT Vs Gemini For Coding: Which AI Fits Your Workflow?
Claude Vs ChatGPT Vs Gemini For Coding: Which AI Fits Your Workflow? Published July 06, 2026
12 vLLM Alternatives for Efficient and Scalable LLM Inference
12 vLLM Alternatives for Efficient and Scalable LLM Inference Published July 06, 2026





















