












Best Claude Model In 2026: How to Choose The Right One?
KEY TAKEWAYS:
- The best Claude model depends on the workload. Choose by reasoning depth, coding needs, latency, cost, context length, and production reliability instead of model reputation alone.
- Use stronger models for complex reasoning and coding. Reserve premium Claude models for architecture, agent workflows, code review, long documents, and high-risk decisions.
- Use faster models for routine production tasks. Classification, summarization, extraction, routing, and support drafts often benefit more from speed and cost control.
- Validate with real prompts before rollout. Benchmark accuracy, latency, token cost, failure modes, and maintainability on your own workflow.
The best claude model in 2026 depends on the job: Claude Opus 4.8 is the strongest current choice for the hardest reasoning, coding, agentic, and knowledge-work tasks; Claude Sonnet 4.6 is the best default for most teams because it balances capability, speed, and cost; and Claude Haiku 4.5 is the fastest, most cost-efficient option for lightweight or high-volume production workflows. This recommendation is current as of June 1, 2026, based on Anthropic’s model overview, release notes, and pricing pages.
Claude model selection should not start with the biggest model. A production team should choose based on reasoning depth, latency target, budget, context size, workflow complexity, and whether the task needs a frontier model or a smaller model orchestrated inside a larger workflow. Anthropic’s current model overview lists Claude Opus 4.8, Claude Sonnet 4.6, and Claude Haiku 4.5 as the current primary model tiers, with Opus 4.8 positioned as the most capable model for complex reasoning and agentic coding, Sonnet 4.6 as the best speed-intelligence balance, and Haiku 4.5 as the fastest model with near-frontier intelligence (Anthropic Claude models overview).
This guide compares the Claude AI model lineup, explains when to use each tier, and gives teams a practical selection framework for coding, writing, analysis, real-time applications, and legacy workflows.
Xem thêm:
- What Is Agentic AI? Benefits, Architecture And How It Works
- How To Build Agentic AI Around Real Workflow Logic
- Enterprise AI Agents: What Matters Before Scaling
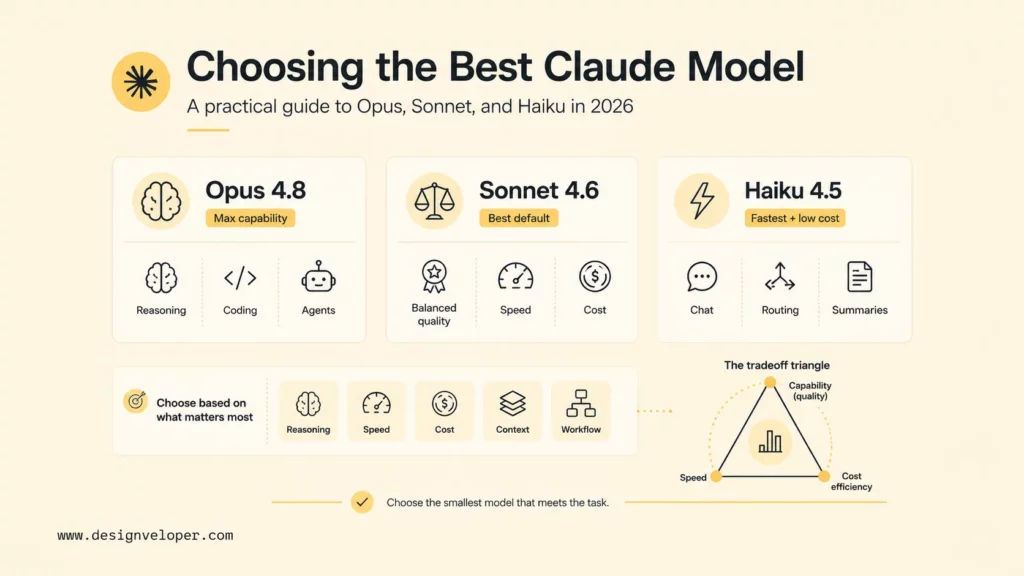
What Is The Best Claude Model Right Now?
The best Claude model right now is Claude Opus 4.8 for maximum capability, Claude Sonnet 4.6 for most everyday and production use, and Claude Haiku 4.5 for speed-sensitive or cost-sensitive workloads. Teams should treat Claude Opus 4.7 and earlier models as compatibility options unless a pinned workflow already depends on them.
Anthropic released Claude Opus 4.8 on May 28, 2026, after the Opus 4.7 release. The current docs list Opus 4.8 with a 1M token context window, 128k max output, adaptive thinking, and standard pricing of $5 per million input tokens and $25 per million output tokens. That makes Opus 4.8 the current top recommendation when a task requires the strongest Claude reasoning and agentic coding performance.
Claude Sonnet 4.6 remains the practical default for many teams. Anthropic describes Sonnet 4.6 as a full upgrade across coding, computer use, long-context reasoning, agent planning, knowledge work, and design, with 1M token context in beta and pricing at $3 per million input tokens and $15 per million output tokens (Claude Sonnet 4.6 release announcement). For many production applications, Sonnet 4.6 gives enough quality at lower cost and faster latency than Opus.
Claude Haiku 4.5 is the best fit when responsiveness matters. Anthropic says Haiku 4.5 offers near-frontier performance with much greater cost efficiency and speed, with pricing at $1 per million input tokens and $5 per million output tokens. Haiku is especially useful for chat, routing, classification, extraction, summarization, and sub-agent work where a larger model would waste budget.

How To Choose The Right Claude Model
The right Claude model is the smallest model that can complete the task reliably within the required quality, latency, context, and governance constraints. A model choice that looks cheaper per request can become expensive if it causes retries, review overhead, tool errors, or poor user outcomes.
Use these decision criteria before choosing a model:
- Reasoning depth: choose Opus for complex architecture, difficult coding, high-stakes analysis, multi-step planning, and tasks where wrong reasoning is expensive.
- Speed: choose Haiku for real-time interactions and Sonnet for a strong balance of quality and responsiveness.
- Cost: compare input, output, cache, and batch pricing before selecting a model for high-volume workflows. Anthropic’s pricing page lists Opus 4.8 and Opus 4.7 at $5/$25 per million input/output tokens, Sonnet 4.6 at $3/$15, and Haiku 4.5 at $1/$5.
- Context needs: use Opus 4.8 or Sonnet 4.6 when the workflow needs a 1M token context window; use Haiku 4.5 when 200k context is enough.
- Workflow complexity: use stronger models for planning, tool use, codebase-scale tasks, and agent orchestration; use smaller models for repeated subtasks.
Anthropic’s own model-selection tutorial warns that a new Claude version is not simply a patch on an old one. Each release is a separate training run, so a task that suited one model may fit another model better after a new release. That is why teams should test real prompts and real workflows before changing production defaults.
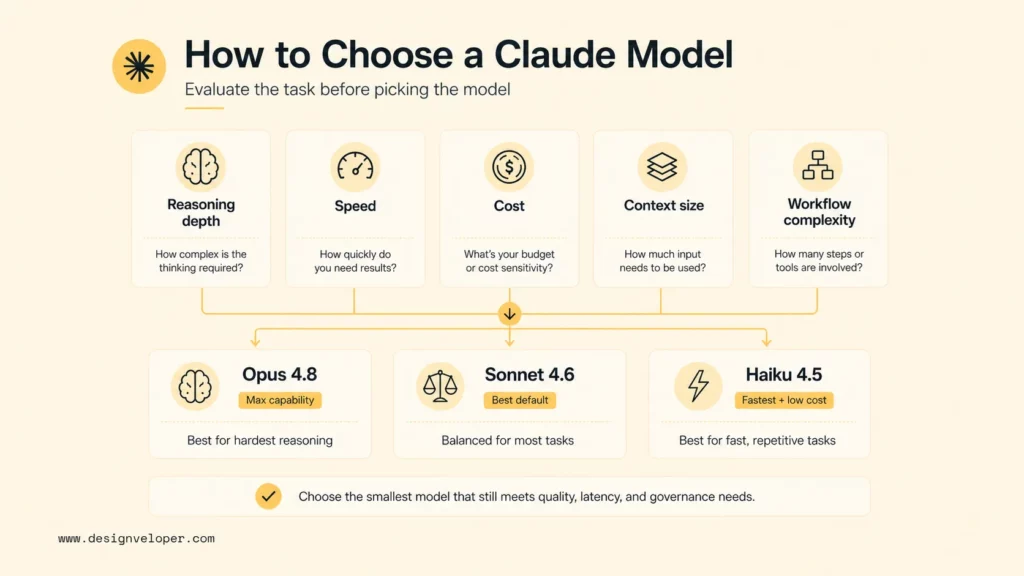
Quick Comparison Of Claude Models
A quick comparison makes the tradeoffs easier to see. The table below focuses on the models a team is most likely to evaluate in 2026, including current models and older models that may remain relevant for pinned workflows.
| Model | Best For | Reasoning Strength | Speed | Cost Position | Typical Use Cases |
|---|---|---|---|---|---|
| Claude Opus 4.8 | Hardest coding, reasoning, agents, knowledge work | Highest current Opus tier | Moderate | Highest current tier | Architecture, codebase migrations, research agents, complex analysis |
| Claude Opus 4.7 | Legacy or pinned Opus workflows | Very high | Moderate | Same list price as newer Opus releases | Compatibility, previously tuned coding workflows, regression-controlled systems |
| Claude Sonnet 4.6 | Most daily production work | High | Fast | Mid-tier | Coding, analysis, long documents, product assistants, agent planning |
| Claude Haiku 4.5 | Fast and high-volume tasks | Medium-high | Fastest | Lowest current tier | Chat, extraction, routing, classification, sub-agents, lightweight coding help |
| Claude Sonnet 4.5 | Existing Sonnet workflows | High | Fast | Mid-tier | Compatibility, evaluated prompts, older production systems |
| Claude 3.7 Sonnet | Older hybrid reasoning workflows | Moderate-high | Fast | Legacy | Existing integrations that have not migrated |
The practical takeaway is simple: start with Sonnet 4.6, move up to Opus 4.8 when the task needs stronger reasoning, and move down to Haiku 4.5 when speed and cost matter more than maximum capability.
Xem thêm:
- AI Chatbot Integration: What Successful Rollouts Usually Need
- AI Agent vs AI Assistant: Which Is the Better Fit?
- AI Chatbot Development: When a Custom Build Makes More Sense
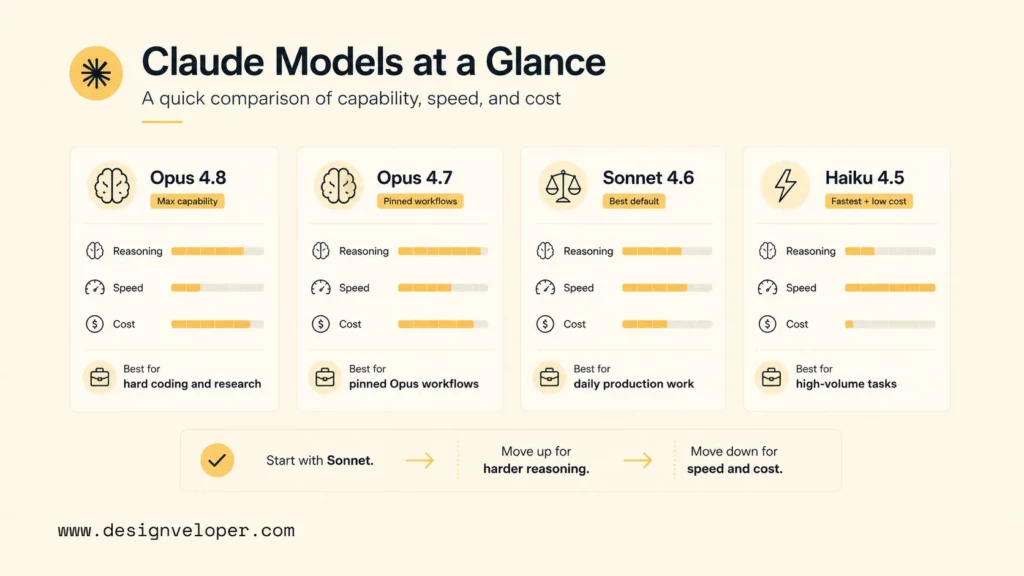
The Best Claude Models In 2026
The best Claude models in 2026 should be ranked by current usefulness, not only by release order. The audit outline below includes several model-specific headings. The recommendations under each heading reflect the current model lineup and explain when older models still matter.
1. Claude Opus 4.8
Claude Opus 4.8 is the strongest current Opus model for new, difficult work. It is the safest answer when a team asks for the best claude model for complex reasoning, long horizon agentic coding, and high autonomy workflows. Anthropic also lists it as its most capable model for complex tasks in the current Claude model overview.
The main reason to choose Opus 4.8 is not novelty. It is capability under pressure. The model is built for work that needs careful planning, large context, tool use, and strong judgment across many steps. Anthropic says Opus 4.8 supports a 1M token context window on the Claude API, Amazon Bedrock, and Vertex AI. It also supports 128k max output tokens and adaptive thinking.
| Item | Claude Opus 4.8 |
|---|---|
| Best for | Complex reasoning, hard coding, agents, enterprise workflows |
| API model ID | claude-opus-4-8 |
| Context window | 1M tokens on Claude API, Bedrock, and Vertex AI |
| Max output | 128k tokens |
| Standard pricing | $5 per million input tokens and $25 per million output tokens |
| Main upgrade | Better long horizon coding, tool triggering, and context handling |
Its benchmark profile supports its role as the premium model. LLM Stats reports that Opus 4.8 scored 88.6% on SWE bench Verified, 69.2% on SWE bench Pro, 74.6% on Terminal Bench 2.1, and 1890 Elo on GDPval AA. These figures point to strong coding, terminal, and knowledge work performance.
- Best For: complex coding, agentic workflows, technical planning, long document analysis, and high stakes knowledge work.
- Usage: use Opus 4.8 when Sonnet 4.6 fails on reasoning depth, context handling, or tool based execution.
- Strengths: strong long context work, adaptive thinking, high output limit, better tool triggering, and stronger performance on hard coding tasks.
- Limitations: higher cost and moderate latency. It is not the default choice for simple or high volume tasks.
2. Claude Opus 4.7
Though now superseded by Opus 4.8, Opus 4.7 was a strong Opus release for advanced software engineering, long-running tasks, instruction following, and vision. Anthropic said Opus 4.7 improved on Opus 4.6 for difficult coding work and was available across Claude products, API, Amazon Bedrock, Vertex AI, and Microsoft Foundry (Claude Opus 4.7 release announcement).
- Best For: pinned workflows that were evaluated on Opus 4.7.
- Usage: keep using it when migration risk is higher than the benefit of upgrading.
- Strengths: strong coding, long-running task handling, instruction following, and agentic reliability.
- Limitations: Opus 4.8 is now the current Opus recommendation for new work.
3. Claude Opus 4.6
Claude Opus 4.6 improved long-running agentic work, large-codebase reliability, code review, debugging, and knowledge-work tasks. Anthropic positioned Opus 4.6 as an upgrade to its smartest model at the time, including a 1M token context window in beta (Claude Opus 4.6 release announcement).
- Best For: existing Opus 4.6 workflows that require stability.
- Usage: keep it only when outputs, latency, or prompts are validated for this model.
- Strengths: deep reasoning, debugging, code review, and large-context work.
- Limitations: newer Opus releases provide a stronger path for new deployments.
4. Claude Sonnet 4.6
Claude Sonnet 4.6 is the best all-around Claude model for many teams in 2026. It offers a strong capability-cost balance for coding, analysis, agent planning, design, and daily knowledge work. The official model overview describes Sonnet 4.6 as the best combination of speed and intelligence (Claude Sonnet 4.6 model overview).
- Best For: most production assistants, coding helpers, document analysis, and team workflows.
- Usage: use Sonnet 4.6 as the first model to test when quality matters but Opus cost is not justified.
- Strengths: balanced reasoning, speed, long context, and predictable production economics.
- Limitations: the hardest coding or research tasks may still justify Opus 4.8.
5. Claude Haiku 4.5
Claude Haiku 4.5 is the fastest and most cost-efficient current Claude model. Anthropic says Haiku 4.5 gives users a new option for near-frontier performance with much greater cost efficiency and can support real-time, low-latency tasks such as chat assistants, customer service agents, and pair programming (Claude Haiku 4.5 performance and pricing).
- Best For: high-volume chat, routing, extraction, classification, summarization, and sub-agent tasks.
- Usage: use it where milliseconds and unit economics matter.
- Strengths: fastest current tier, lowest current price, and strong enough for many structured tasks.
- Limitations: not the best choice for the hardest reasoning, broad research, or complex codebase work.
6. Claude Opus 4.5
Claude Opus 4.5 was a major Opus release for coding, agents, computer use, deep research, slides, and spreadsheets. Anthropic introduced Opus 4.5 in November 2025 with API pricing at $5 per million input tokens and $25 per million output tokens, making Opus-class capabilities less expensive than earlier Opus 4.1 pricing (Claude Opus 4.5 release announcement).
- Best For: older Opus-class workflows where the team has not upgraded.
- Usage: retain only when regression tests show it still performs better for a specific prompt set.
- Strengths: strong agentic coding, computer use, and knowledge-work capability for its release period.
- Limitations: superseded by Opus 4.6, Opus 4.7, and Opus 4.8 for new model selection.
7. Claude Sonnet 4.5
Claude Sonnet 4.5 was a strong coding and agent model in late 2025. Anthropic described Sonnet 4.5 as a leading model for agents, coding, and computer use when it launched (Claude Sonnet 4.5 release announcement).
- Best For: teams with evaluated Sonnet 4.5 prompts or integrations.
- Usage: keep it when a production workflow depends on stable outputs.
- Strengths: strong coding, computer use, and agentic performance.
- Limitations: Sonnet 4.6 is the better default for new work.
8. Claude Sonnet 4
Claude Sonnet 4 improved on Sonnet 3.7 and was useful for coding, assistants, and high-volume tasks when Claude 4 first launched. Anthropic’s current pricing page marks Claude Sonnet 4 as deprecated, so new applications should avoid choosing it unless a cloud or enterprise environment still requires it (Anthropic pricing and deprecation notes).
- Best For: short-term compatibility.
- Usage: migrate when practical.
- Strengths: historically strong general-purpose Sonnet performance.
- Limitations: deprecated status and weaker capability than Sonnet 4.6.
9. Claude Opus 4
Claude Opus 4 is also listed as deprecated on Anthropic’s current pricing page. It may still appear in older documentation, internal model registries, or cloud configurations, but it should not be the default choice for new Claude model selection.
- Best For: legacy evaluation continuity only.
- Usage: keep only while migration is scheduled and tested.
- Strengths: earlier Opus-class reasoning and coding capability.
- Limitations: deprecated and materially behind current Opus releases.
10. Claude 3.7 Sonnet
Claude 3.7 Sonnet was important because it introduced hybrid reasoning behavior for many users, but it is now an older model for most production decisions. Teams may still keep it where old prompts, compliance testing, or evaluation baselines are tied to the 3.7 generation.
- Best For: older hybrid-reasoning workflows and benchmark continuity.
- Usage: use only when migration risk is documented.
- Strengths: stable behavior for teams that already validated it.
- Limitations: weaker than current Sonnet and Opus models for most new tasks.
11. Claude 3.5 Sonnet
Claude 3.5 Sonnet was a widely used earlier Claude model, but it should now be treated as a legacy option. It may remain relevant for old integrations, cost assumptions, or archived evaluations, but it is not the recommended model for new 2026 deployments.
- Best For: legacy integrations with strict output compatibility.
- Usage: maintain only while a migration plan is underway.
- Strengths: familiar behavior and mature prompt history for older teams.
- Limitations: older capability, smaller context assumptions, and weaker fit for agentic workflows.

Which Claude Model Fits Different Use Cases Best?
The best Claude model for each use case depends on whether the workflow needs reasoning quality, response speed, low cost, long context, or stable compatibility. The table below gives a practical starting point.
Best Claude Model For Coding And Engineering Work
Claude Opus 4.8 is the strongest choice for the hardest coding and engineering work, especially codebase-scale changes, complex debugging, architectural reasoning, and long-running agentic tasks. Claude Sonnet 4.6 is the better default for day-to-day coding assistance, pull request explanation, test generation, and implementation support where cost and latency matter.
For engineering teams, the best Claude model for coding is often a two-model workflow: Sonnet 4.6 handles most iteration, while Opus 4.8 reviews hard problems, migration plans, or high-risk changes.
Best Claude Model For Writing, Analysis, And Daily Team Tasks
Claude Sonnet 4.6 is the best fit for writing, analysis, and daily team tasks in many organizations. It has strong reasoning, long-context capability, and more favorable pricing than Opus. Use Opus 4.8 when the work requires deep synthesis across large, ambiguous, or high-stakes materials.
Haiku 4.5 can support lighter writing tasks such as summaries, extraction, rewrite variants, ticket triage, and first-pass classification. A team can then reserve Sonnet or Opus for final reasoning and review.
Best Claude Model For Real-Time And High-Volume Applications
Claude Haiku 4.5 is the best Claude model for real-time and high-volume applications. It is the fastest current tier and has the lowest current pricing among the primary model family. That makes Haiku 4.5 a strong fit for customer-facing chat, routing, classification, extraction, autocomplete, and small sub-agent tasks.
Production teams should still test quality. A low-cost model is only cheaper if it produces acceptable results without excessive retries, escalations, or human corrections.
Best Claude Model For Legacy Workflows And Existing Integrations
The best Claude model for legacy workflows is the model that has already passed the team’s regression tests. If a workflow is stable on Opus 4.7, Sonnet 4.5, Claude 3.7 Sonnet, or Claude 3.5 Sonnet, the team should not migrate blindly just because a newer model exists.
Legacy model decisions should be temporary and documented. A migration plan should include prompt retuning, side-by-side evaluation, cost comparison, safety review, and rollback criteria.
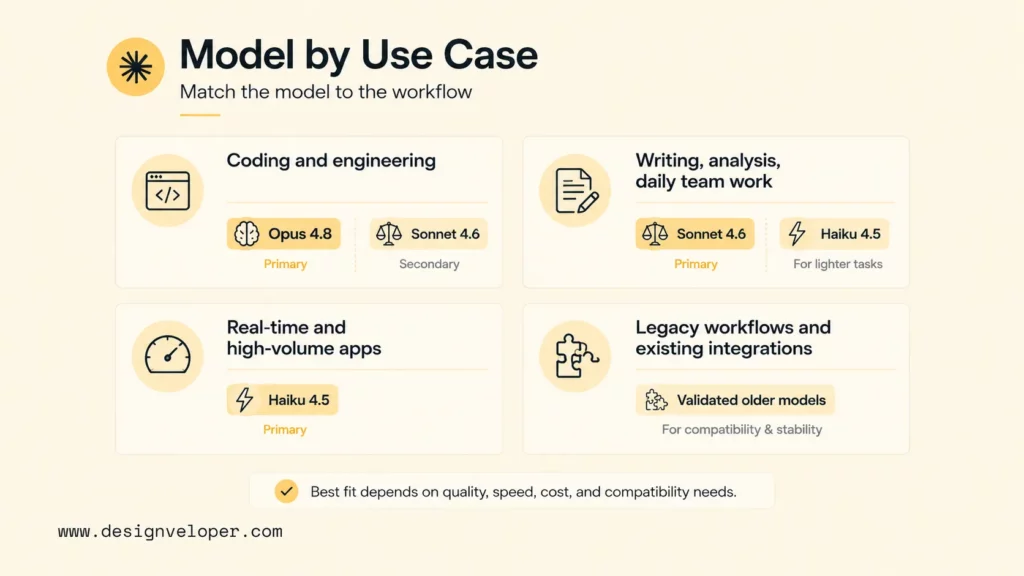
When To Upgrade, Downgrade, Or Stay With An Older Claude Model
Upgrade when a real capability gap appears. A team should move to Opus 4.8 if the current model struggles with complex code, long-horizon planning, advanced analysis, or high-stakes reasoning. A team should move to Sonnet 4.6 if an older Sonnet model creates quality, context, or instruction-following limits.
Downgrade when latency, cost, or throughput matters more than maximum intelligence. If Sonnet produces reliable answers for a task, using Opus may waste budget. If Haiku produces reliable classifications or summaries, using Sonnet may also waste budget.
Stay with an older Claude model when compatibility matters more than novelty. Some production systems depend on stable output formats, approval workflows, audits, or regulatory documentation. In those cases, teams should keep the older model until a controlled migration proves that the newer model improves outcomes without breaking the workflow.
Use this upgrade checklist before changing models:
- Run the new model on real prompts and edge cases, not only benchmark-style examples.
- Compare output quality, latency, cost, tool behavior, refusal behavior, and format stability.
- Review whether prompts need retuning because new models can interpret instructions differently.
- Measure downstream human correction time, not only token price.
- Roll out in stages and keep rollback paths for customer-facing workflows.

What This Means For Teams Using Claude In Production
For teams using Claude in production, the best Claude model is not always the newest or largest one. The practical choice is the model mix that gives reliable outcomes at acceptable cost, latency, and operational risk.
Designveloper approaches AI model selection as part of broader product engineering. A Claude-powered product still needs workflow mapping, prompt design, tool boundaries, evaluation datasets, human review, logging, and maintenance. Designveloper’s public AI development services show this broader delivery context: AI capability becomes business value when it is integrated into real software, not only tested in a chat window.
In production, teams often get better results by matching different Claude models to different workflow layers:
- Opus 4.8: complex planning, difficult coding, strategic analysis, and high-risk review.
- Sonnet 4.6: daily production assistant work, coding support, analysis, document tasks, and agent planning.
- Haiku 4.5: routing, extraction, classification, summaries, and low-latency sub-agent tasks.
Designveloper’s public Song Nhi virtual assistant project is a useful example of assistant-style product thinking because the product centers on conversational workflows and user-friendly task handling. The public page should not be read as proof that Claude was used. The safer lesson is that AI assistants need model selection, workflow design, context handling, and user review to work well in real life.
A strong production strategy also avoids one-model thinking. Teams should build evaluation suites that compare models on the actual tasks they care about: support response accuracy, code review usefulness, document extraction quality, tool-call safety, workflow completion, and user satisfaction. That evidence is more useful than assuming the newest model is automatically the best fit.

FAQs About Claude Models
Is Claude 4 Or 3.7 Better?
Claude 4-era models are generally better choices than Claude 3.7 Sonnet for new work because they offer stronger coding, reasoning, agent, and long-context capabilities. Claude 3.7 Sonnet may still matter for legacy workflows that depend on its behavior, but new applications should usually evaluate Sonnet 4.6, Haiku 4.5, or Opus 4.8 first.
Is Claude 4.5 The Best?
Claude 4.5 models are no longer the top current recommendation as of June 1, 2026. Presently, Claude Opus 4.8 is the top Opus recommendation, Sonnet 4.6 is the best all-around default, and Haiku 4.5 remains the current fast, low-cost Haiku option. Claude 4.5 models can still matter for compatibility and evaluated workflows.
Which Claude Model Is The Most Intelligent?
Claude Opus 4.8 is the most capable generally available Claude model listed in Anthropic’s current model overview. It is the best starting point for the hardest reasoning, coding, agentic, and knowledge-work tasks. Claude Sonnet 4.6 may still be the better operational choice when cost and speed matter.
Should You Still Use Older Claude Models?
Teams should use older Claude models only when they have a clear reason, such as stable output compatibility, completed validation, cloud availability constraints, or migration risk. For new work, teams should normally start with Sonnet 4.6, test Opus 4.8 for hard tasks, and use Haiku 4.5 for high-volume or low-latency tasks.
How Do You Know When To Switch Claude Models?
Switch Claude models when testing shows a measurable improvement in quality, cost, latency, safety, or workflow completion. Do not switch only because a model is newer. Run side-by-side evaluations with real prompts, compare correction effort, test tool behavior, and roll out gradually with rollback criteria.

Also published on

Share post on










Related Articles

AI Chatbot Development: A Step-By-Step Guide
AI Chatbot Development: A Step-By-Step Guide Published July 15, 2026
15 Best AI No-Code App Builders In 2026 (No Coding Skills Required)
15 Best AI No-Code App Builders In 2026 (No Coding Skills Required) Published July 06, 2026
Best ChromaDB Alternatives For RAG And Vector Search
Best ChromaDB Alternatives For RAG And Vector Search Published July 06, 2026





















