












Vector Databases vs Traditional Databases: Key Components Comparison
In today’s era, data is a golden asset for any business to better understand its customers, competitors, and operational efficiency. It’s scattered everywhere, and to make full use of this valuable treasure, you need essential tools to store, organize, and find it effectively. Traditional (relational) and vector databases are such crucial tools. So, what are the main differences between vector databases vs traditional databases? You’ll find the answer in today’s blog post!
Why Comparing Vector Databases and Traditional Databases Matters in the Era of AI, Search, and Big Data
In recent years, we’ve been witnessing the growing adoption of AI, big data analytics, and large-scale search across domains. These factors have contributed to changing how businesses keep and use information.
By understanding vector databases vs traditional databases, as well as their key differences, you can choose the right tool strategically for your specific use cases.
How? Different data models serve different goals. They come with unique capabilities to handle big data, perform large-scale search, and support AI applications.
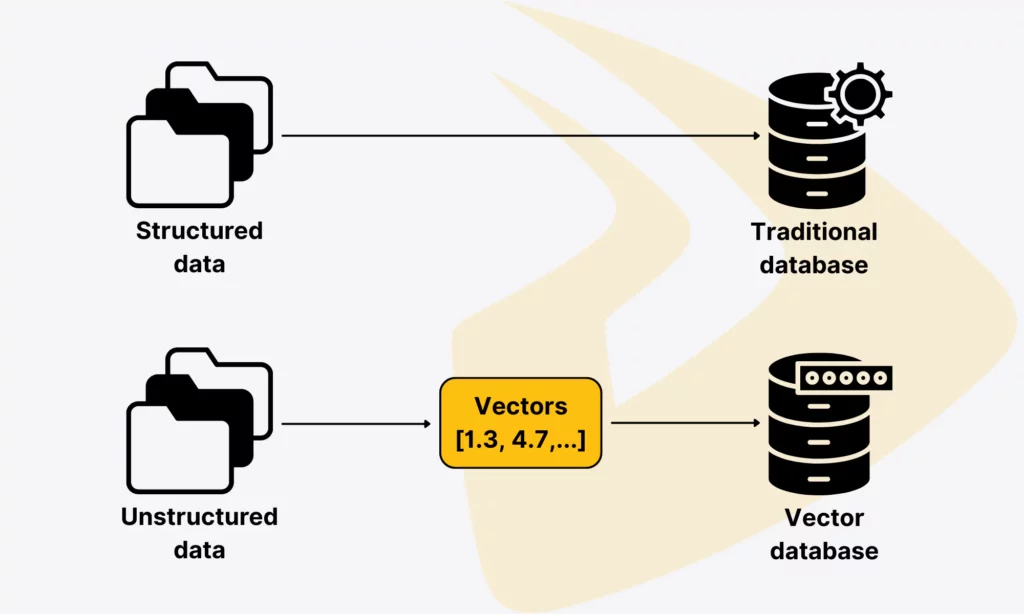
Traditional databases
Legacy databases (often relational types) organize data into orderly tables. Each table has clear-cut columns that define where to place dates, numbers, and text.
They’re strict about structure, which means no room for freeloaders or messy entries. If your data doesn’t fit their schemas, it’s eliminated instantly.
These systems are built to uphold the ACID principles (Atomicity, Consistency, Isolation, Durability) to handle every transaction reliably. Further, they aim to find data with 100% precision – all thanks to their exact keyword searches.
SQL is a common query language you often use to search, sort, or tweak records within traditional databases.
Vector databases
Vector databases, on the other hand, contain embeddings in a high-dimensional vector space. These embeddings are numerical values of unstructured data, including text, images, audio, and videos.
- Vector databases mainly focus on approximate nearest neighbor (ANN) searches rather than exact matches. They use various indexing techniques to ensure low latency, high throughput, and memory efficiency.
- Vector databases work by calculating the distance between the stored embeddings and a query vector in an n-dimensional space. The closer, the more relevant. This approach allows vector databases to store unstructured data and perform similarity search, even when the given query uses synonyms and paraphrases.
Vector databases play a very important role in the AI and machine learning landscape.
According to the 2025 Dremico report, 88% of respondents claimed the importance of data access in developing AI solutions faster. Organizations consider high-quality, AI-ready data management as their strategic priority. They’re actively looking for a technological solution to reduce complexity and increase efficiency in storing, governing, securing, and using data.
This is where vector databases shine. They help you store, index, and consume growing volumes of unstructured data, from lengthy documents to customer reviews and social media posts. By representing this data in numbers, they let you search and retrieve the essential information to perform specific tasks, like answering customer support questions or finding legal documents.
Key Components Comparison of Vector Databases vs Traditional Databases

To better understand the main differences between vector databases vs traditional databases, you should compare them in various factors. These factors include the data types they handle, querying approaches, performance optimization, scalability, and integration with AI solutions.
Data Type Handled
Traditional relational databases, like MySQL or PostgreSQL, excel at processing structured data, which is neatly organized in tables. They’re ideal for transactional data, typically customer information, orders, financial records, or product inventories. This data often represents explicit relationships and has well-defined schemas.
With this capability, traditional databases are a perfect choice if you want to ensure data consistency and integrity. Further, it works best for exact matching.
Note: Traditional databases can store high-dimensional data. But they perform slow searches for it, especially when the dimension count is too large.
Meanwhile, vector databases, like Pinecone, Milvus, or ChromaDB, are built to store, manage, and search high-dimensional embeddings. These vectors often represent unstructured data. By converting this data into numerical values and storing them in a vector space, these databases can capture their meaning and similarity instead of exact values.
This capability allows vector databases to store any type of unstructured data, whether text, images, audio, or videos. They’re ideal if you want to perform semantic searches across multimodal data, handle natural language queries, or recommend similar items.
Query Methods
You often use SQL (Structured Query Language) to interact with traditional databases and conduct various activities therein. This language allows you to create and adjust database structures, upsert or delete data, and perform querying tasks.
So, how do traditional databases use SQL to query data? Upon connecting to the databases, you can write SQL queries to specify the data you want to extract based on different criteria. Such statements as SELECT, FROM, WHERE, or JOIN let you filter, sort, and join data from various tables.
For example, you can retrieve the name and price of all products costing less than 500 from a products table by sending the SQL query like this:
SELECT product_name, priceFROM productsWHERE price < 500With this capability, traditional databases prove extremely useful in complex joins, aggregations, conditional filtering, and transactional workloads demanding exact values.
By contrast, vector databases rely on ANN algorithms like IVF (Inverted Files) or HNSW (Hierarchical Navigable Small World) to perform similarity searches. These algorithms don’t help you find exact keywords, but the most similar items based on vector distance. This allows you to expand the search scope and enable high-speed, memory-efficient searches, but at a cost of accuracy.
Additionally, beyond numerical vectors, several databases support storing and filtering metadata to increase search performance. This makes them beneficial in real-world applications where both semantic search and exact matches are equally crucial, like legal services or healthcare.
For instance, you can ask vector databases to “find cases about personal freedoms being violated in the US from 2020-2025.” The databases will return all semantically relevant cases, which are filtered within the scope of the United States from 2020 to 2025.
Performance Optimization
Traditional databases rely heavily on various techniques to improve performance and enable efficient data manipulation. These core techniques include:
- B-tree Index: This data structure organizes data in a balanced tree. This allows the databases to look for a specific row faster by moving directly to the needed section rather than wasting time on scanning the entire table.
- Hash Index: This data structure maps a key (e.g., a customer ID) to a particular location. This makes it ideal for finding values that accurately match specific conditions (e.g.,
WHERE id = 123). - Query Planners: When you send a SQL query, the planners decide how to perform that query. Particularly, it identifies which indexes to use or whether to filter rows or join tables first, and then pick the most effective route based on table sizes, cost estimates, and index availability.
With these techniques, traditional databases can perform well in extracting structured data and processing transactional workloads.

Vector databases use various indexing techniques, like HNSW graphs or product quantization, to accelerate similarity searches, even under heavy load. Some core techniques include:
- Inverted File Index groups vectors in subsets so that vector databases only find the top-K subsets for a query vector.
- Graph-Based (HNSW, NSG) Indexes create a point network with connections and follow these links to search for the nearest neighbors faster.
- Product Quantization (PQ) aims to shrink vector size for less space usage and quicker distance measures. It’s ideal if you have massive amounts of vectors, and keeping all the embeddings in full precision wastes a lot of memory.
When data or query volumes increase considerably, these techniques still quickly locate the closest vectors with memory-efficient usage.
Scalability
Traditional databases scale best vertically. When data volumes increase, you can add more resources (storage, RAM, etc.) to a single server and expand its memory usage efficiently.
However, it struggles to deal with horizontal scaling. If you want to distribute growing data volumes across multiple servers added to the databases and use techniques like sharding, it’s possible but challenging, as traditional databases strictly follow ACID rules.
- These ACID guarantees regulate that all servers must keep the same schemas (like columns or data types) and keep copies in sync.
- If you want to update data on one server, the system also has to update its corresponding copies on other servers to ensure all the same data shares the same result.
- While data updates happen, no other transaction should interfere or see half-finished changes.
- When a change is made, it must remain even when any server reboots.
Coordinating all these ACID promises across various servers requires complex management for distributed transactions. That extra complexity makes horizontal scaling harder for traditional relational databases.
Meanwhile, vector databases are natively designed for horizontal scaling. They provide built-in distributed architectures, data sharding, cluster management, etc., to split and distribute massive volumes of vector embeddings across servers.
Vector databases also support vertical scaling by letting you increase the memory and storage resources of a single node to process a larger load. However, this approach is inherently limited in these databases due to hardware constraints and single points of failure. Therefore, the databases still prioritize horizontal scaling.
Integration with Modern AI Pipelines
Modern AI pipelines are the end-to-end workflows that collect data, train models, and deliver predictions.
Integrating traditional databases with these modern pipelines is often indirect and requires extra layers (e.g., middleware or plugins).
If AI solutions work mainly on structured data (like rows of numbers or text), traditional databases work fine. But in practice, AI systems require much more than simple structured data.
These systems, especially LLM-based applications, often leverage unstructured data to perform NLP tasks, like answering customer support questions, retrieving medical research, or suggesting similar items. Traditional relational databases, however, are not optimized to store, index, and search through large amounts of vectors embedded from unstructured data.
Meanwhile, vector databases have that ability. They integrate seamlessly with machine learning and LLM systems through built-in connectors.
Accordingly, they can connect with neural networks to automatically embed unstructured data, with LLMs to fuse relevant vectors for response generation, and with other AI frameworks (e.g., LangChain or LlamaIndex) for advanced applications like RAG or personalized recommendations.
These capabilities make vector databases an integral component of modern AI pipelines.
Comparison Table of Vector Databases vs Traditional Databases
Below is a comparison table summarizing the different components between vector databases vs traditional databases:
| Key Component | Vector Databases | Traditional Databases |
| Data Type Handled | High-dimensional vectors that represent the numerical values of unstructured data | Structured data |
| Query Methods | Similarity search using ANN algorithms; also supports metadata filtering | SQL for exact matches |
| Performance Optimization | Various indexing techniques, like IVF, HNSW, or product quantization, for faster vector searches and retrieval | B-tree/Hash indexes, query planners, caching |
| Scalability | Horizontal scaling | Vertical scaling |
| AI Integration | Integrate seamlessly with AI/ML pipelines | Limited to AI tasks that mostly handle tabular modeling |
Pros and Cons of Vector Databases and Traditional Databases
Given a detailed comparison of vector and traditional databases, you may have a better understanding of these tools. Each comes with pros and cons, giving your business unique edges and trade-offs to manage data effectively.
Traditional databases
Traditional databases bring various benefits to your business:
- Rich Query Language (SQL): With SQL, you can instantly pull up “sales of product A across Europe last quarter where customer ratings topped 4.8,” all without writing custom code from scratch. Just select, join your tables, filter, and let relational databases do the rest.
- Reliability: Relational databases enforce ACID compliance to ensure data integrity. In real-world applications (e.g., banking systems) where data consistency, regulatory compliance, and zero tolerance for mistakes are non-negotiable, this capability is essential.
- Scaling: When data volumes go up, traditional databases let you scale vertically without restructuring your current system.
- Operational Maturity: Databases like Oracle and PostgreSQL have gained decades of real-world experience and rich ecosystems of extensive backups, robust monitoring, and security best practices. When your workload gets heavy, these databases still keeps running smoothly.
However, traditional databases still have their own limitations:
- Limited Processing of Unstructured Data: Traditional databases excel at handling structured, table-based data. But they struggle with unstructured data.
- Horizontal Scaling Complexity: Due to ACID principles, relational databases face difficulties in handling growing data beyond one server.
- Less Effective AI Integration: Traditional databases perform less effectively in modern AI/LLM applications.
Vector databases
Vector databases benefit your business in various aspects:
- Excellent Handling of Unstructured Data: Vector databases, such as Pinecone or ChromaDB, are very good at storing, indexing, and managing high-dimensional vectors from unstructured data. This capability makes it ideal for semantic search and advanced AI applications (e.g., RAG or recommendation systems).
- Quick Similarity Search: Vector databases search for nearest neighbors and deliver LLMs the most relevant content for context-aware responses. Their built-in indexing techniques and ANN algorithms also allow for high-speed, memory-efficient searches, even across billions of records.
- Native Horizontal Scaling: Vector databases are inherently designed for effective horizontal scaling with built-in sharding, cluster management, and replication. These capabilities allow them to spread data across multiple nodes, ensuring their excellent performance even under growing load.
- AI-Native: Vector databases offer built-in connectors with machine learning models (for embedding or reranking), LLM frameworks (e.g., LangChain or Haystack), and model inference tools (e.g., Ollama or vLLM). This connection makes vector databases a crucial component of AI pipelines.
However, vector databases still present several unavoidable challenges:
- Extra Data Pipeline: A data pipeline is a set of tools that ingest, transform, store, manage, and update data. Vector databases themselves don’t cover all these data management tasks, but just a key component in this data pipeline. Their main goal is just to store and search vector embeddings. They don’t take care of storing raw data input, metadata, etc., but combine with other tools (relational databases, object storage, etc.) to handle these tasks.
- Less Maturity in Operations: Compared with decades-old relational databases, vector databases are less mature. Therefore, they may have less tooling and fewer experienced administrators.
Scenarios Best Suited for Vector Databases and Traditional Databases

Given the key differences mentioned above, vector databases and traditional databases best fit different situations.
When to Use a Vector Database?
Vector databases are the backbone of unstructured data processing and semantic or similarity search at scale. So, they work best if your business prioritizes these two factors and can afford a vector database’s trade-offs (less accuracy but higher speed and lower memory efficiency).
Some ideal use cases of these databases include:
- AI-powered search and retrieval: Such AI applications as NLP systems or chatbots rely on vector embeddings to search contextually relevant information, whether text, images, or speech.
- Example: A medical research tool (like PubMed) finds and extracts relevant biomedical literature similar to a doctor’s query.
- Recommendation systems: Use vector databases to search and suggest similar items to a user’s interests or browsing habits.
- Example: Streaming platforms like Netflix recommend suitable content for your preferences based on your watching histories.
- Computer vision and multimedia: Compare vector similarity to perform image or video search.
- Example: An e-commerce website like Shoppe allows buyers to upload a photo of bags to search for visually similar products.
- Real-time Extraction: RAG systems or dynamic customer support bots pull the most similar knowledge-base entries to deliver context-aware, factually grounded answers.
When to Use a Traditional Database?
Traditional databases work best if you want to handle structured data and workloads that require strong data integrity and complex transactional logic.
Below are several ideal situations for traditional databases:
- Transactional systems: Banking platforms, inventory management, and e-commerce order processing require traditional databases for reliable transactions.
- Example: A banking app uses relational databases to record a credit-card payment in a single transaction to prevent mismatched balances.
- CRM and ERP: Traditional databases help these enterprise systems manage customers, vendors, human resources, and financial records.
- Example: A company’s ERP database keeps employee payrolls and supplier invoices updated consistently across departments.
- Reporting and analytics on structured data: Business Intelligence (BI) dashboards, compliance reports, or financial audits demand powerful SQL queries and aggregations.
- Example: A BI tool combines structured data from sales, customer, and inventory tables to create quarterly revenue reports.
- Regulatory and security-critical environments: Healthcare, legal, or governmental applications must enforce ACID rules and strict schemas to meet compliance and privacy requirements.
Hybrid Cases
Instead of using these databases separately, you can combine them in various modern applications. This combination is ideal if your application requires both vector databases for AI integration and relational databases for structured data consistency.
For example, an e-commerce application stores customer profiles, orders, and inventory in a traditional database. Further, it can integrate a vector database to process product-image embeddings and recommendation queries.
Meanwhile, an intelligent knowledge assistant keeps text-based embeddings in a vector database for similarity search and document summarization. Additionally, it can use a relational database to store document metadata (author, timestamps, etc.) to narrow down the search scope.
Future of Databases in the AI Era
As more and more organizations plan to deploy AI initiatives across their workflows, the way they collect, manage, and use data will change as well. Accordingly, databases evolve to meet the growing demands of AI-powered applications.
At present, we’re witnessing several key trends shaping the future of databases in the AI era:
- Native support for vectors in traditional databases
- Various traditional relational databases, like PostgreSQL or Oracle, have integrated native features for vectors. These features help traditional databases store embeddings, apply distance metrics, and perform vector search, along with other relational or JSON queries.
- Hybrid and multimodal database architectures
- Hybrid systems like ArcNeural are being developed to process mixed data types: structured (transactions, graphs), unstructured (text documents), and vectors. ArcNeural uses a storage-compute separated architecture to support graph queries, vector indexing, real-time handling, etc.
- Meanwhile, TigerVector – a system integrated in TigerGraph – supports both vector search and graph query. This system aims to implement hybrid searches that leverage unstructured and structured data seamlessly in ways previously unattainable.
Conclusion
You now have a solid overview of vector databases vs traditional database, from what they are, how different they are, and where they shine in today’s AI-driven landscape.
But here’s the thing: by themselves, vector or traditional databases aren’t the full story. Their real value comes out when you pair them with the right technologies and expertise, creating seamless, high-performance AI solutions.
Looking for a partner to actually make that happen? That’s where Designveloper steps in. With 12 years on the market and a team of more than 100 skilled professionals, we’ve built a reputation as Vietnam’s top software and AI development company.
We deliver custom, scalable AI systems tailored to your business needs, whether it’s medical software that keeps nurses updated on patient health, AI-powered support ticket automation using LangChain and OpenAI, or e-commerce chatbots that don’t just answer questions, but actually drive conversions.
Our clients trust us for our clear communication, on-time delivery, and strong focus on user experience. If you’re ready to upgrade your current software with advanced AI integration, Designveloper is ready to help you move forward with confidence. Let’s start building the future, together.
Also published on

Share post on










Related Articles

Claude Vs ChatGPT Vs Gemini For Coding: Which AI Fits Your Workflow?
Claude Vs ChatGPT Vs Gemini For Coding: Which AI Fits Your Workflow? Published July 06, 2026
12 vLLM Alternatives for Efficient and Scalable LLM Inference
12 vLLM Alternatives for Efficient and Scalable LLM Inference Published July 06, 2026
Cross-Platform App Development: Build Apps For Multiple Platforms
Cross-Platform App Development: Build Apps For Multiple Platforms Published July 01, 2026





















