












How to Choose the Right Vector Database for Your AI Project?
Vector databases have become more popular, as they facilitate data storage, indexing, and search. Are you looking for the right vector database for your app, but don’t know which one to opt for? If so, this article is the right place for you! Keep reading and explore the best criteria to choose the right vector database to avoid unexpected failures and enhance your app’s performance!

Why Does Choosing the Right Vector Database Matter?
Vector databases are an important component in various LLM-powered systems and RAG applications. They are powerful containers that store, index, and search for vector embeddings. These embeddings are converted using machine learning models to express the meaning and relationships within unstructured datasets in numerical formats.
Unstructured data, like customer reviews or PDF documents, is hard to process with traditional databases (that specialize in processing structured data). Therefore, vector databases appear and help businesses absorb this data easily.
Also, these databases extend the inherent capabilities of LLMs. Instead of being bound to pretrained data, LLMs can access up-to-date and relevant information from external data sources through vector databases.
By comparing the stored embeddings and a query vector in a high-dimensional space, vector databases can identify data that is contextually similar to the given query. For this reason, LLMs can return factually grounded and relevant answers.
With these capabilities, vector databases have become increasingly popular. Their global market records an estimated CAGR of 23.38% from 2025 to 2032, reflecting growing demands and competitiveness.
However, among a variety of vector databases available, which one should you choose is a hard-to-answer question.
Selecting the wrong vector database can lead to unexpected consequences. It shapes the performance of your LLM-powered applications. So, a poor choice can limit scalability, slow query & search speed, and increase costs over time.
Additionally, vector databases don’t work independently, but with other components of a complex AI system. The right database can provide flexible APIs, SDKs, and integrations with your existing infrastructure. Not to mention that for mission-critical applications, choosing the right database can ensure robust encryption and backup options to always protect sensitive vector data and ensure data consistency.
Key Criteria for Choosing Vector Database
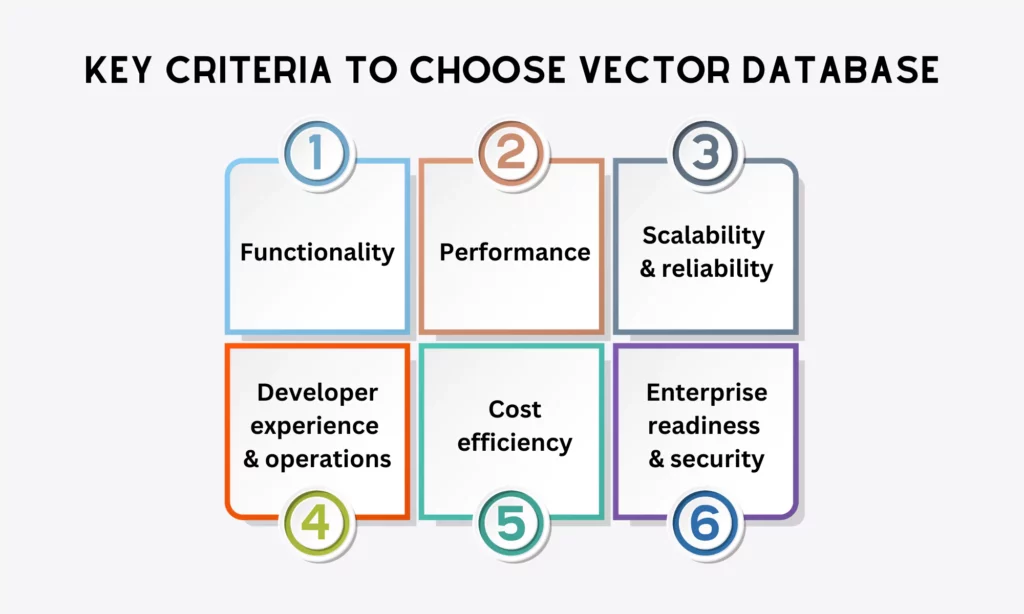
So, how can you choose the right vector database for your AI project? No matter what your specific use cases are, consider the following criteria:
Functionality
When choosing a vector database, the first thing that pops up in your mind may be its functionality. Common vector databases now offer plenty of features to support data storage, indexing, and search. Among them, here are several noticeable functionalities you should consider:
Hybrid search
Vector databases mainly search for the most accurate or relevant vectors to a given query, instead of performing exact keyword matches.
Having said that, some databases like Pinecone still support Flat indexing for brute-force search, enabling hybrid search for real-time applications like legal services or healthcare support. In these use cases, beyond contextually relevant information, the responses need to contain exact terminologies to avoid misunderstanding.
Metadata filtering
Vector databases don’t store only numerical values of data points, but also structured metadata for filtering purposes. Beyond semantic search, these databases apply query conditions (e.g., title, categories, languages, or timestamps) to narrow down the search scope.
CRUD operations
CRUD stands for Create, Read, Update, and Delete. These actions are a crucial part of vector databases:
- Create: When fresh data comes, you need to embed it and add new vectors to a database. This action keeps your data always current and searchable.
- Read: This means retrieving (reading) the stored vector embeddings and applying metadata (if any) for specific tasks.
- Update: When new data arrives or changes, you need to upload or update corresponding vectors to a database without downtime or costly reindexing.
- Delete: When user data is no longer essential or violates privacy regulations, it needs to be removed. A good database comes with reliable delete operations to keep the index clean and ensure compliance.
Various vector databases now support CRUD operations to ensure consistent data flows, long-term scalability, and regulatory compliance. However, vector indexes like FAISS don’t inherently provide full CRUD operations. So, when using this search library, you need to consider building extra components to support CRUD.
Similarity metrics
Similarity metrics measure how close the stored embeddings are to a query vector. The higher the similarity metrics are, the more relevant the two vectors are. Vector databases now support various metrics (e.g., Euclidean, Cosine, or Inner Product) and let you combine or switch between them when requirements change.
Multimodal data support
Many applications now require similarity search for multimodal data beyond text, like healthcare apps that need to interpret medical images. Honestly, vector databases don’t directly involve embedding such data, as their main tasks are to store, index, and search. They can work on any data types as long as your chosen embedding models can convert data into the formats they can read.
However, to facilitate the embedding process, many vector databases already integrate embedding models and let you call them through their supported programming languages. When you use a database’s hosted embedder, it’ll automatically transform the data without the need to switch between tools.
If you don’t plan to embed data externally but your app works mostly on multimodal data, choose the vector database supporting it.
Performance
You should choose a vector database whose performance meets your specific requirements (e.g., low latency or high accuracy). When evaluating a database’s performance, you should look at the following factors:
Accuracy
Vector databases can’t ensure 100% accuracy as they work mostly on ANN (Approximate Nearest Neighbor) or kNN (k Nearest Neighbor) searches. However, a good database offers a wide range of search algorithms or indexing techniques (e.g., Inverted Files or Hierarchical Navigable Small World) to deliver the most precise results while ensuring high speed. It can also allow you to tune parameters to balance speed, memory efficiency, and accuracy.
Latency
Latency refers to the time a database takes to return a response after a query. The lower latency the database has, the better. This is extremely crucial for real-time applications where users expect instant results. If a vector database responds slowly to a request, it can ruin consistent workflows and reduce user experiences with the apps.
Throughput (QPS)
Throughput refers to the number of requests a vector database can process per second under load. This factor is often measured by QPS (Queries Per Second). High throughput means that the database can serve many users or handle many queries concurrently without delays. Large-scale or enterprise-grade systems like RAG applications often require high throughput, even during traffic spikes.
Indexing efficiency
Another factor used to evaluate a vector database’s performance is its indexing efficiency. This factor measures how resource-efficiently an index organizes high-dimensional vector embeddings to perform fast, yet precise ANN searches.
There are many things significantly affecting indexing efficiency, from the number of vector dimensions and algorithm choice to data size and deployment options (local or cloud-based). Choose a suitable database if your apps require minimal resource usage (i.e., for memory and computations) but still balance search speed and recall.
Scalability and reliability

Choosing the right vector database shouldn’t consider only temporary benefits, but also the long-term growth of your applications. So, don’t ignore the scalability and reliability of a database.
Scalability
Data or request volumes rarely remain unchanged. When your application evolves, so does the vector database to handle increasing amounts of data or traffic.
Vector databases should support long-term scalability through horizontal scaling, distributed architecture, indexing techniques (HNSW, LSH), vector compression, and more. These features allow you to add more servers or distribute data and workload across multiple nodes. This helps you handle increased data volumes and concurrent queries without interrupting performance.
Elasticity
Elasticity refers to the ability to automatically scale up or down resources based on current demand. This on-demand flexibility lets the database optimize infrastructure costs and keep performance consistent.
High availability and fault tolerance
What if the system fails to work due to power loss or hardware issues? You may face data loss and work session interruptions. That’s why a good vector database needs to provide replication, clustering, and backup options to ensure high vector availability and fault tolerance.
For example, replication refers to creating and keeping various copies of the data across multiple servers. So, when one server fails, other replicas can continue to work on queries and ensure service consistency.
Developer experience and operations
The right vector database should align with the technical capabilities of your development team. Further, it needs to provide tools and integrations to support seamless, effective operations. Below are some operational features you should consider in a vector database:
Deployment options
How does your team want to deploy a vector database (e.g., as a fully managed service or in a private cloud)? Some providers like Milvus offer flexible deployment options to help you meet performance, data security, and compliance requirements.
For example, Milvus Lite is a lightweight version you can install and run on your local device. Meanwhile, Zilliz Cloud acts as a managed version of Milvus and takes care of all the database-level operations, letting your team focus on developing your core apps.
APIs and SDKs
Your chosen vector database needs to provide clean, well-maintained APIs and official SDKs. These tools allow your team to add, manage, and search for vectors easily with different programming languages.
Further, with stable APIs, the way you code to interact with the database will keep working, even when the database is upgraded or when you migrate data to another system. This, therefore, reduces development time, minimizes errors, and maintains backward compatibility.
Integration ecosystem
Vector databases don’t work alone, but are integrated with other tools or frameworks to create seamless AI workflows. You can use it as a crucial component in RAG pipelines, complex agentic systems, or analytics tools.
If a vector database can’t seamlessly work with essential tools or your existing infrastructure, you can’t get the most value from it. So, don’t ignore the supported integrations of vector databases to choose the right one for your project.
Documentation and community support
Even when a vector database is easy to use, install, and deploy, it doesn’t mean it has no issues. So, to ensure your seamless installation and effective debugging when any issues arise, your chosen vector database has to offer clear documentation and strong community support. This helps you work with that database smoothly.
Monitoring and observability
After deploying and using a vector database, you may want to monitor its performance, resource usage, and query latency. So, instead of using external tools for monitoring and observability, you can check whether the database offers built-in tools to track performance metrics and diagnose issues in real-time. This will ensure reliable and consistent performance of the database and reduce downtime.
Cost efficiency

Cost efficiency is another crucial factor to evaluate a vector database. It not only limits to how much money you pay for initial investments (e.g., licensing, hosting, or advanced features), but also extends to how the database uses resources and stores vectors for resource savings. This is very crucial if you choose a database for long-term scalability.
Pricing model
There are many kinds of vector databases in the market, typically open-source and proprietary (closed-source).
- Open-source vector databases allow you to use, modify, and distribute their code without cost. But you have to pay for hosting and other incurred costs for operations (if any).
- Proprietary databases, meanwhile, rarely let you tune their code, but often come with free plans or tiers (with limited features).
If you have just started with vector databases, we advise you to use open-source databases or free tiers of proprietary counterparts.
In case you move to paid plans, consider whether the database offers transparent pricing models. This helps you avoid unexpected charges when data or query volumes grow.
Resource utilization
Using memory and network bandwidth efficiently also reduces infrastructure costs, even if your chosen database works locally or on cloud servers. Various vector databases provide optimized indexing, compression methods, and other features to use resources efficiently.
Storage techniques
High-dimensional vectors may take a large space. This increases infrastructure costs when your data volumes grow. Choose a vector database that can address this issue by offering advanced storage techniques (e.g., approximate indexing, compression, or tiered storage) to minimize storage usage.
Enterprise readiness and security
If you want a vector database for production-ready applications instead of pure experimentation, consider enterprise readiness and security as well.
Security and compliance
For production workloads, your vectors may contain sensitive or confidential information. If improperly secured, your company may face data leakage, loss of user trust, and even regulatory penalties. So, work with vector databases that offer strong security measures and comply with standards (e.g., GDPR or HIPAA).
Availability and SLAs
Your app needs to access data all the time to provide fast responses. So, consider whether your chosen vector database offers features like replication, multi-region deployment, or automated failover to ensure high data availability. Further, evaluate how the provider’s SLA (Service Level Agreement) guarantees high performance and uptime for their service.
Technical support
What if a vector database has technical issues? In this case, you may need direct, always-on support from the provider to offer quick resolutions. The provider, accordingly, should provide clear, detailed FAQs and professional technical support 24/7 to minimize downtime and ensure smooth operations.
Tips For Making the Right Choice of Vector Database

Beyond the criteria we mentioned above, you can use the following tips to improve the choice of vector database for your AI project:
First, define clear use cases. Each vector database comes with a set of features for specific applications, like information retrieval, RAG pipelines, or recommendation systems.
Without well-defined goals, you hardly take full advantage of these functionalities for your application. So, clarify what problems your app needs to solve and how vector databases help achieve that.
For example, RAG systems may require high throughput and low latency in vector searches and retrieval. Meanwhile, for video FAQ assistants, a vector database needs to handle multimodal embeddings efficiently and support suitable similarity metrics.
Second, ponder long-term costs. The overall cost of vector databases doesn’t only involve initial setup, but covers other long-term factors, like resource usage, maintenance, and operations. So, to prevent budget overruns and painful scalability, you should include all the possible costs beyond initial installation.
Third, evaluate the learning curve. Your team may not want to use vector databases, which take a lot of time to understand, unless you’re just exploring or experimenting with the databases. For production-ready applications, prioritize a vector database with a short learning curve, ease of development, clear documentation, and even strong community support.
Last but not least, try open-source databases or free tiers of proprietary tools before committing to paid plans. This helps you evaluate their search speed, accuracy, and compatibility with your current systems.
Conclusion
Vector databases are increasingly crucial in various real-world applications, like real-time information retrieval, image & video search, and RAG systems. However, choosing the wrong database can lead to data leaks, high latency, and memory waste. That’s why you should assess the following criteria to choose the right vector database for your specific use case:
- Functionality
- Performance
- Scalability
- Developer experience and operations
- Cost efficiency
- Enterprise readiness and security
But vector databases don’t work independently. They’re crucial components in a much more complex system. In case you’re looking for a reliable partner in building such systems integrating vector databases, Designveloper is worth considering!
We’re one of the leading software development and IT consulting companies in Vietnam. Our dedicated team has more than 10 years of hands-on experience in building simple chatbots to complex agentic applications. We master 50+ cutting-edge technologies, including LangChain, CrewAI, and AutoGen, and have completed 200+ successful projects across industries.
We don’t only focus on a specific tech stack, but prioritize a combination of the right technologies, from vector databases to LLMs, to create complete, smart systems. These systems streamline our clientele’s workflows and enhance user experiences. Some of our notable projects include LuminPDF (an online tool for PDF editing and sharing), OCD (a remote patient monitoring platform), etc.
We work on proven Agile frameworks to deliver applications on time and within budget. With commitment to quality and good communication across channels, we received positive customer reviews on reputable review platforms like Clutch (with a 4.9 rating).
Do you want to discuss your idea further? Contact us now! Let’s realize your idea together, whether it’s for information retrieval, product recommendations, or multimodal search.
Also published on

Share post on










Related Articles

What Is Deep Learning? How It Helps AI Learn From Data
What Is Deep Learning? How It Helps AI Learn From Data Published May 15, 2026

The Impacts of AI on Modern Data Integration
The Impacts of AI on Modern Data Integration Published May 04, 2026Read more topics

AI Development
AI Development
AI/Machine Learning
AI/Machine Learning

Automation Technologies & Solutions
Automation Technologies & Solutions

Back-End Development
Back-End Development

Best Companies
Best Companies

Blockchain Technology and Applications
Blockchain Technology and Applications

Business Analyst Role & Skills
Business Analyst Role & Skills

Chatbot Development
Chatbot Development

Cloud Technology Revolution
Cloud Technology Revolution

CMS Platforms Development
CMS Platforms Development












