












Build A RAG Chatbot From Local Prototype To Production Deployment
To build a rag chatbot that works beyond a demo, teams need more than a prompt, a vector database, and a chat screen. A reliable RAG chatbot needs clean source data, sensible chunking, embeddings, retrieval logic, an LLM integration, evaluation tests, access control, monitoring, and a deployment plan. This guide walks from a local prototype to production deployment so developers and product teams can ship a chatbot that answers from trusted knowledge instead of guessing from model memory.
Retrieval-augmented generation is useful when the chatbot must answer from private, fresh, or domain-specific information. A support bot can search help articles. An internal assistant can answer from policy documents. A document chatbot can summarize uploaded PDFs and point users to the relevant section. Designveloper’s guide to what retrieval-augmented generation means is a helpful primer, while this article focuses on the build path, failure points, and production decisions.
A practical RAG chatbot should be treated like a software system. Retrieval quality, data permissions, latency, cost, logs, feedback, and source citations are part of the product, not optional polish. The best prototype is one that teaches the team what must be hardened before users depend on the answers.
Fast decision guide: use RAG when the chatbot must answer from source material the business controls. Do not start with RAG only because the topic sounds technical; start with RAG when retrieval, citations, freshness, permissions, and source updates are part of the product requirement.
| Reader goal | Best starting architecture | First proof to build | Launch risk to review |
|---|---|---|---|
| Internal policy or HR assistant | RAG over curated policies with role-aware filters | Answer 30-50 real employee questions with correct source citations | Country, role, and version permissions |
| Customer support chatbot | RAG over help-center articles, release notes, and escalation SOPs | Retrieve the right article before generating the answer | Outdated answers and unsupported refund or pricing claims |
| Document or PDF chatbot | RAG with section-aware chunking and source previews | Summarize and answer from specific sections, not whole files | Private document exposure and weak OCR parsing |
| Developer knowledge assistant | Hybrid search over docs, tickets, changelogs, and code references | Return the exact doc, API page, or ticket that supports the answer | Stale indexes after code and documentation changes |
| Production business workflow | RAG service with authentication, observability, evaluation, and feedback | Pass retrieval, citation, latency, security, and fallback tests | Unmeasured quality drift after launch |
What Is A RAG Chatbot?
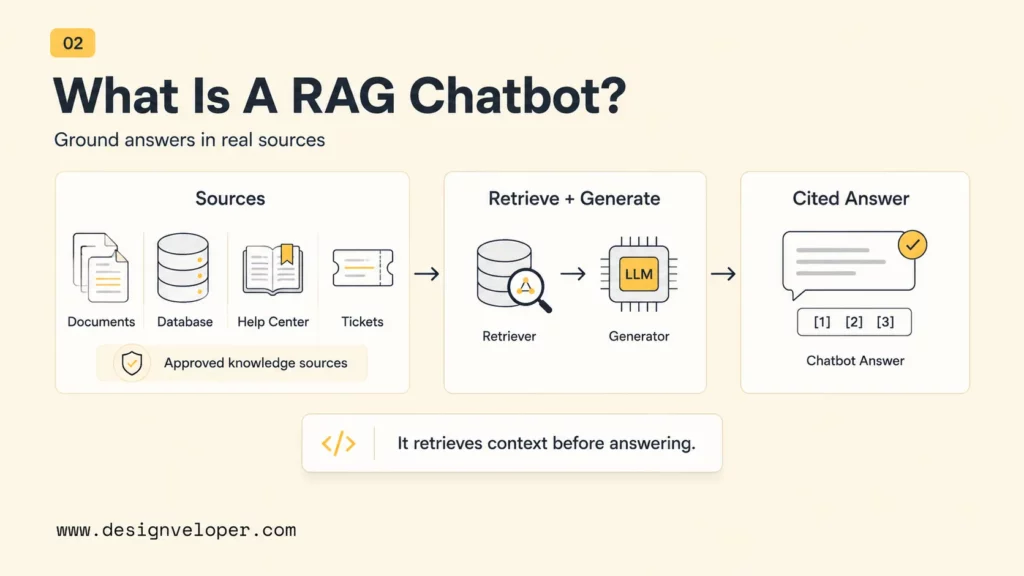
A RAG chatbot is a conversational application that retrieves relevant information from a knowledge source before asking a language model to answer. RAG stands for retrieval-augmented generation. The chatbot first searches documents, databases, help centers, tickets, policies, or other approved content. The chatbot then sends the retrieved context and the user’s question to an LLM so the final response can be grounded in the source material.
The basic idea is different from a normal chatbot that answers only from its model training. A general model may know broad concepts, but it may not know a company’s latest pricing, internal procedures, contract clauses, or product release notes. A RAG chatbot gives the model a live context window so it can use current and private knowledge at response time.
Modern RAG implementations often use a vector store, embeddings, a retriever, and a prompt template. The LangChain RAG tutorial describes RAG as a way to build Q&A chatbots over specific source information, and the LlamaIndex RAG documentation explains the same pattern through indexing, retrieval, and response generation.
RAG is not magic fact-checking. If the retriever finds the wrong chunks, the model can still produce a wrong answer. If the source documents are outdated, the answer may be outdated. If users are allowed to retrieve documents they should not see, RAG can expose sensitive information. A good RAG chatbot therefore combines retrieval engineering, product design, and security review.
Why Teams Build RAG Chatbots
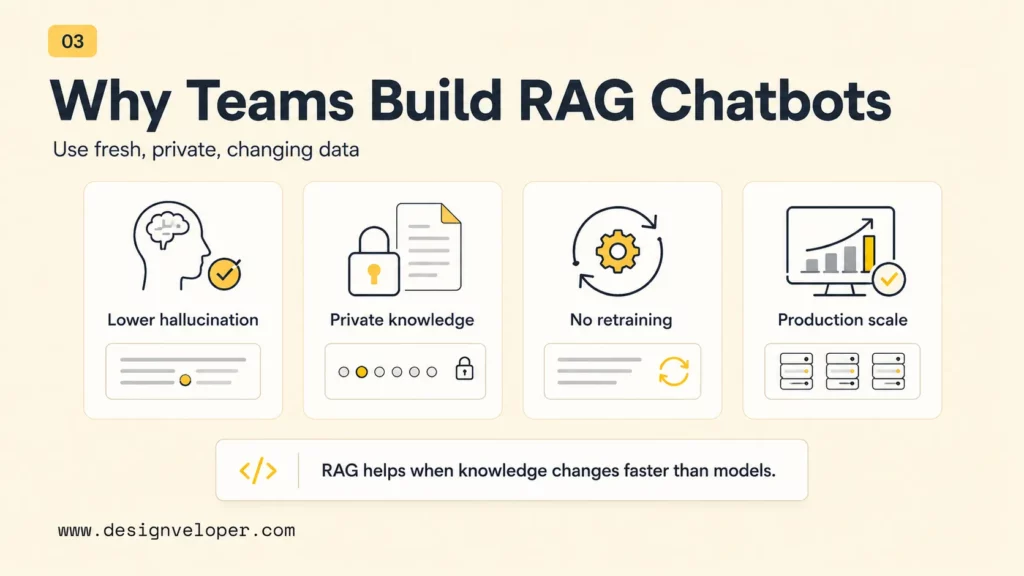
Teams build RAG chatbots because business knowledge changes faster than model training data. RAG lets a chatbot use source content that the team controls without retraining the base model every time a policy, product page, API guide, or legal document changes. The pattern is especially useful for support, HR, finance, legal operations, education, healthcare workflows, sales enablement, and internal knowledge search.
- Reduce hallucinations by grounding answers in source content. A RAG chatbot can answer with retrieved snippets, document names, and citations instead of relying only on model memory.
- Answer from private, updated, or domain-specific data. RAG can connect an LLM to product manuals, internal policies, SOPs, invoices, PDFs, CRM notes, and knowledge bases.
- Improve relevance without fully retraining the model. Updating the source index is often faster and cheaper than fine-tuning for every content change.
- Support both small prototypes and production systems. A local document chatbot can start with a few files, while a production version can use cloud storage, vector indexes, user permissions, and monitoring.
RAG is often the right first step when the main problem is knowledge access. Fine-tuning is more useful when the model must learn a style, task format, or domain behavior that retrieval alone cannot solve. Designveloper’s comparison of RAG versus fine-tuning can help teams choose between those approaches before committing to architecture.
How A RAG Chatbot Works
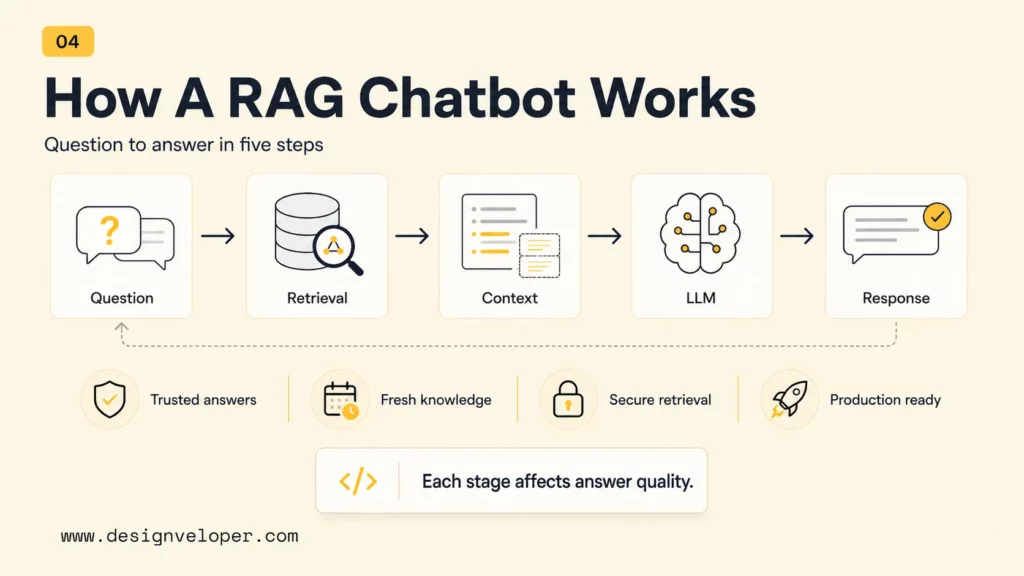
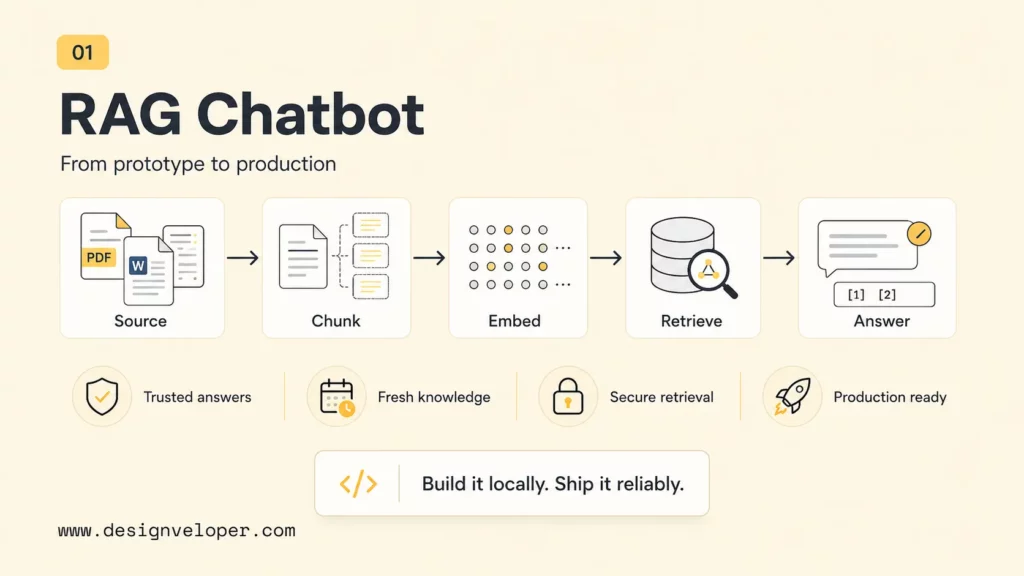
A RAG chatbot works by turning source content into retrievable units, searching those units for the user’s query, and giving the best context to a language model. The workflow looks simple on a diagram, but every stage affects answer quality. Bad parsing creates bad chunks. Bad chunks create weak retrieval. Weak retrieval creates vague or unsupported answers.
RAG chatbot answer pipeline
User asks in natural language.
Query embedding searches approved chunks.
Top chunks, metadata, and permissions are assembled.
The model answers from retrieved context.
The UI shows answer, sources, and fallback.
The pipeline matters because each stage has a different failure mode. Retrieval quality depends on chunking and metadata, while answer quality depends on the prompt, model behavior, source display, and fallback rules.
Ingest And Prepare Source Data
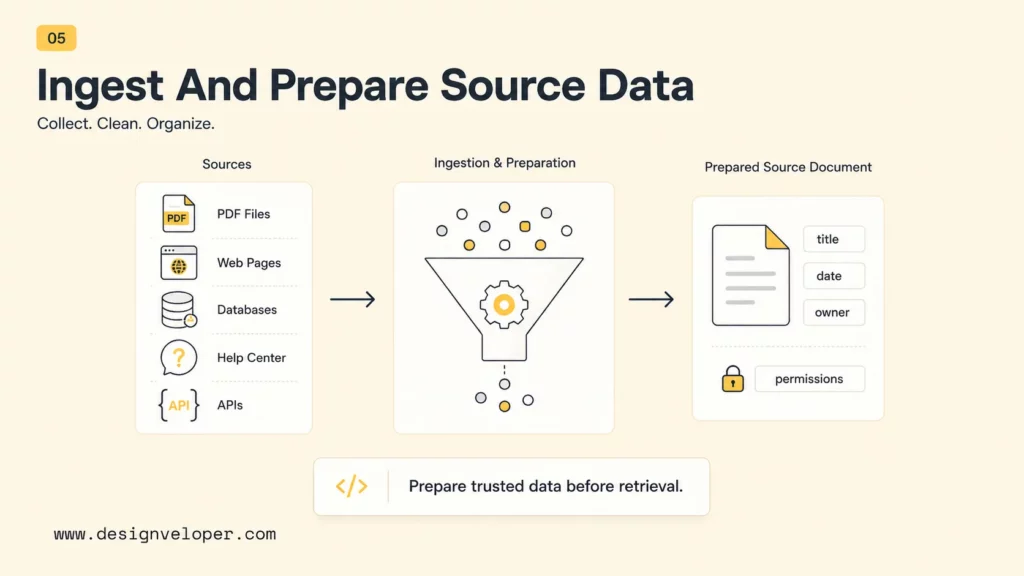
Ingestion loads approved knowledge into the system. Source data may come from PDFs, Markdown files, HTML pages, Google Drive exports, Notion pages, SharePoint folders, database rows, support tickets, product documentation, or internal APIs. The first production decision is which sources are authoritative and which sources should be excluded.
Preparation includes parsing, cleanup, deduplication, metadata extraction, and permission mapping. A document title, section heading, publication date, owner, product, customer segment, and access level can all become useful retrieval metadata. The LlamaIndex ingestion documentation frames this stage as loading, transforming, indexing, and storing data, which is the right mental model for teams coming from ETL work.
Split Content Into Useful Chunks
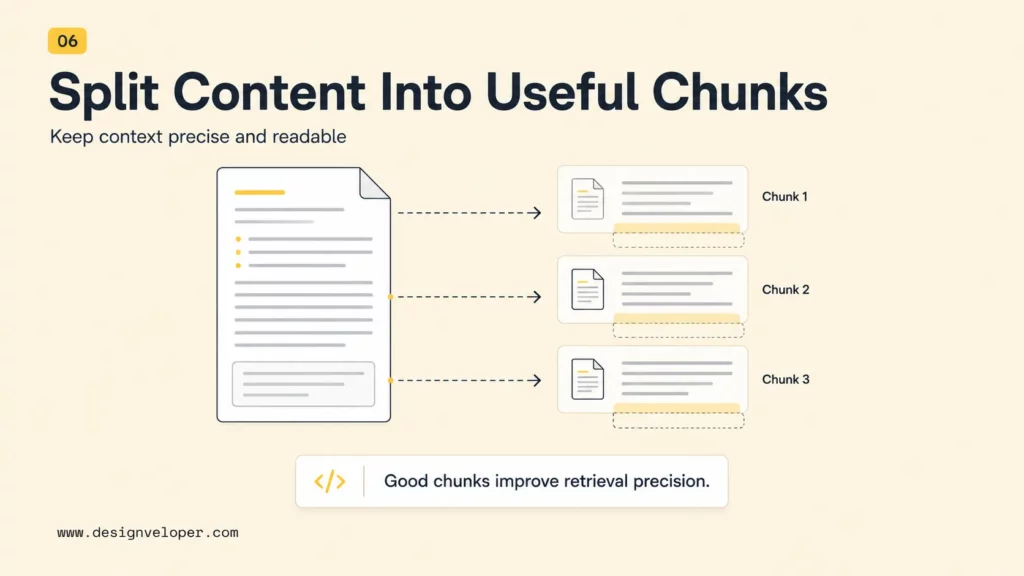
Chunking breaks long content into smaller pieces that fit retrieval and model context limits. A chunk should be large enough to preserve meaning but small enough to retrieve precisely. For example, a full policy document may be too broad, while one isolated sentence may lose the rule’s conditions and exceptions.
Chunking strategy depends on the content. FAQ pages may work with question-and-answer chunks. Contracts may need clause-level chunks with headings. Technical docs may need section-aware chunks that keep code blocks near explanations. The Pinecone chunking guide explains why chunk size and boundaries affect relevance, latency, and retrieval quality in RAG workloads.
Turn Chunks Into Embeddings
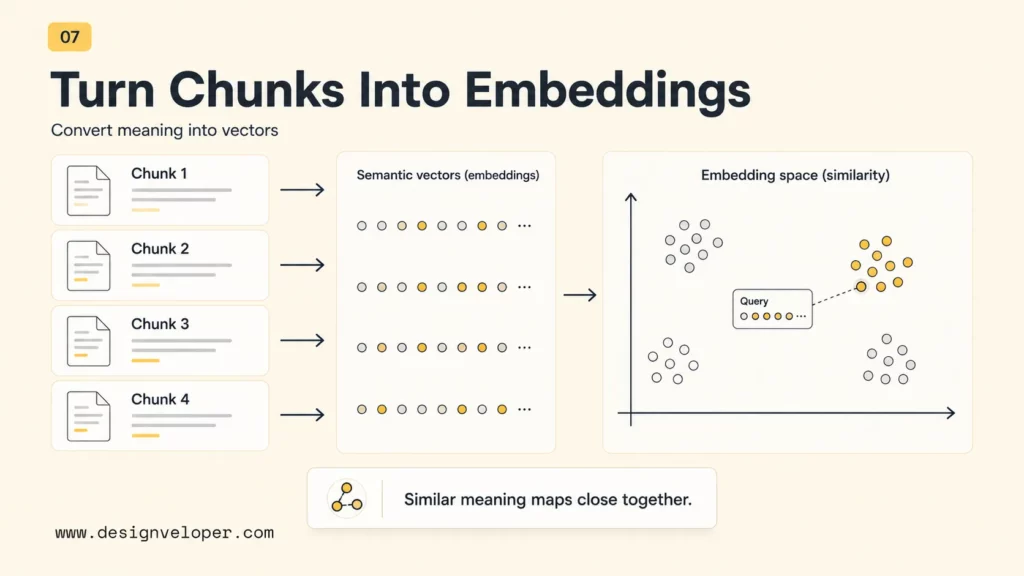
Embeddings turn text chunks into numerical vectors that capture semantic meaning. When the user asks a question, the system embeds the query and searches for chunks with similar vectors. This allows the chatbot to find conceptually related content even when the user does not use the exact source wording.
Embedding model choice matters. A general embedding model may work for help-center search, while a technical or multilingual use case may need stronger testing across real queries. Teams should keep the embedding model, chunking method, metadata schema, and source version together so index changes can be reproduced.
Store And Retrieve Relevant Context
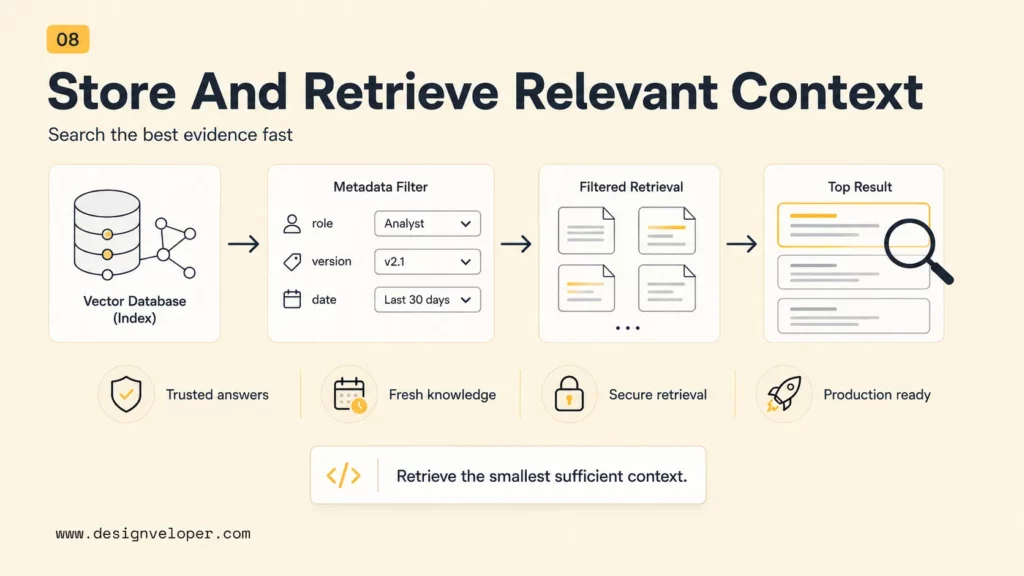
A vector database or vector-capable store holds the embedded chunks and metadata. Retrieval may use vector similarity, keyword search, metadata filters, hybrid search, reranking, or a combination. A support chatbot might filter by product version before semantic retrieval. A HR assistant might filter by country, employee role, and policy effective date.
The OpenAI retrieval documentation describes vector stores as indices for semantic search, while the Pinecone RAG overview explains how chunks, embeddings, and vector search fit together. The key production rule is to retrieve the smallest sufficient context, not the largest pile of loosely related text.
Send Retrieved Context To The LLM
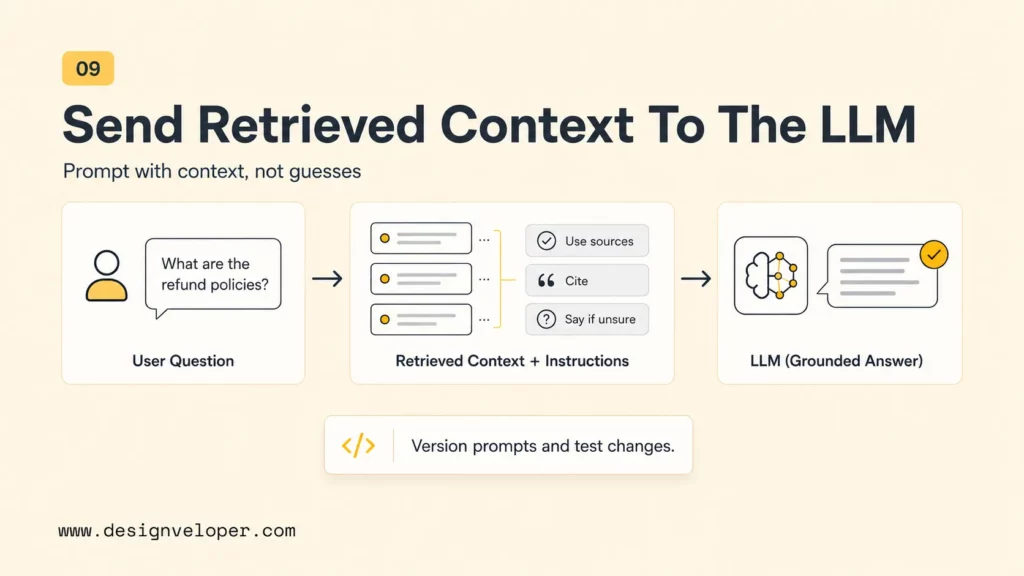
The application sends the user question, retrieved context, and instructions to the LLM. The prompt should tell the model how to use the sources, how to say it does not know, how to cite retrieved context, and how to handle conflicts. A RAG prompt should not ask the model to invent missing facts.
For production use, the prompt should be versioned like code. Changing the prompt can change answer behavior even when the retrieval layer stays the same. Teams should test prompt changes against a regression set of real questions before release.
Return A Final Answer With Sources Or Context

The final answer should be useful and auditable. A customer-facing chatbot may cite article titles or help-center links. An internal document chatbot may show source snippets with file names and section headings. A regulated workflow may require the chatbot to show exact source passages and confidence signals before a user acts.
Source display also improves trust. Users can inspect where the answer came from, and reviewers can debug weak responses. A citation that points to the wrong chunk is not cosmetic failure; it is evidence that retrieval or answer generation needs work.
The Build Path From Prototype To Chatbot
The safest build path starts small, proves retrieval quality, then adds product and operations features. A local prototype should answer a narrow set of questions from a controlled dataset. A production chatbot should add authentication, logging, evaluation, feedback, deployment automation, and data refresh.
Prototype-to-production build path
Use case, users, sources, risks.
Parse, clean, chunk, embed.
Retrieve, prompt, cite, fallback.
UI, auth, feedback, testing.
Refresh, monitor, evaluate, improve.
This build path keeps the first version narrow enough to test. A team should not add memory, agents, or complex UI before retrieval quality and source governance are measurable.
Step 1: Define The Use Case And Data Sources
Start by naming the exact job the chatbot must perform. “Answer questions about our company documents” is too broad. “Help support agents answer refund-policy questions from the latest help-center and internal escalation guide” is specific enough to design and test.
A useful starting brief should include the target users, top tasks, approved source systems, forbidden source systems, response style, languages, risk level, and success metrics. A RAG chatbot for internal onboarding has different standards than a customer-facing chatbot that may influence purchases or compliance decisions.
| Decision | Example choice | Why it matters |
|---|---|---|
| Primary users | Support agents | Defines tone, permissions, and workflow handoff |
| Source data | Help center, escalation SOP, release notes | Controls what the bot can truthfully answer |
| Forbidden data | Private customer records without role checks | Prevents accidental exposure |
| Success metric | Grounded answer rate and agent satisfaction | Measures quality beyond demo appeal |
Step 2: Ingest, Clean, And Chunk The Data
After the use case is clear, build the ingestion pipeline. A local prototype can load a folder of PDFs or Markdown files. A production system should pull from a controlled source, track document versions, handle deleted content, and rebuild the index when content changes.
Cleaning should remove navigation text, repeated headers, broken OCR fragments, boilerplate, and irrelevant footers. Chunking should preserve headings, tables, and sections when those structures affect meaning. If the chatbot must answer from documents with strict sections, keep section names in metadata and expose them in citations.
A practical local pipeline might parse files, split by headings, create 500-900 token chunks with overlap, attach metadata, embed each chunk, and write records into a vector store. The exact numbers should be tested, not copied blindly, because legal clauses, API docs, and support FAQs behave differently.
Step 3: Build Retrieval And Connect The LLM
Build retrieval before spending too much time on chat UI. A simple command-line test should show the top retrieved chunks for each sample question. If the correct chunks are not retrieved, the chatbot will not answer well no matter how polished the interface looks.
Connect the LLM only after retrieval has a baseline. The first prompt should be strict: answer only from provided context, cite the source, and say when the context is insufficient. Frameworks such as LangChain and LlamaIndex can speed up this wiring, while cloud tutorials such as Google Cloud’s RAG chatbot with GKE and Cloud Storage show how the same concept can move toward cloud deployment.
Step 4: Add Memory, UI, And Testing
Memory should be added carefully. Conversation memory helps users ask follow-up questions, but it can also drag old assumptions into a new query. A safe pattern is to store short conversation state separately from retrieved source context and make it clear when the bot is using prior turns.
The UI should show enough context for trust. Useful controls include source links, copied answer feedback, “not helpful” feedback, escalation to a human, conversation reset, and document filters. Testing should include happy paths, ambiguous questions, outdated documents, missing answers, permission boundaries, and adversarial prompts.
Step 5: Deploy And Monitor
Deployment turns the prototype into an operated service. A production setup needs a backend API, a vector store, an LLM provider or local model server, authentication, secrets management, logging, rate limits, retry behavior, and observability. A containerized app can run behind a web UI, internal tool, Slack-style bot, or customer portal.
Monitoring should track retrieval latency, LLM latency, token usage, cost, failed retrievals, empty answers, citation quality, user feedback, and top unanswered questions. Without monitoring, teams discover problems only after users lose trust.
Local Build Vs Cloud Deployment
Local and cloud RAG deployments solve different problems. Local prototypes are fast, private, and inexpensive for early testing. Cloud deployments are better when multiple users need access, data refresh must be automated, or the system needs uptime, scaling, and security operations.
The deployment choice is easier when the team compares the main constraint instead of debating local versus cloud in general.
| Constraint | Local prototype fits when… | Cloud deployment fits when… |
|---|---|---|
| Privacy | The team needs to test private documents without sending data to a hosted model or service. | The team has approved cloud controls, encryption, IAM, logging, and vendor review. |
| Scale | One developer or a small pilot group is validating retrieval quality. | Multiple users need reliable access, uptime, refresh jobs, and shared indexes. |
| Cost | The main cost is experimentation time and local hardware. | The team needs predictable hosting, model usage controls, monitoring, and support. |
| Operations | The system can tolerate manual rebuilds and informal testing. | The system needs CI/CD, secrets management, backups, alerting, and incident response. |
Local LLMs Work Well For Fast Prototyping
Local development is useful for experiments with document parsing, chunking, retrieval, and prompt design. A developer can run a local vector store, use a small open-source model, and test whether the chatbot can answer from a folder of files before choosing a production stack.
Local models can also support privacy-sensitive prototypes because documents do not need to leave the development environment. The tradeoff is hardware, speed, model quality, and maintenance. A local model may be slower, weaker at reasoning, or harder to serve reliably than a managed cloud model.
Cloud Deployment Fits Shared And Scalable Use Cases
Cloud deployment fits teams that need shared access, scheduled ingestion, authentication, autoscaling, backups, monitoring, and integration with existing data systems. Google Cloud’s RAG-capable generative AI reference architecture shows a production-style pattern using GKE, Cloud SQL, and open-source tools.
A cloud setup also makes it easier to separate environments. Development, staging, and production should have different indexes, API keys, logs, and access rules. That separation prevents a test ingestion job from corrupting a production knowledge base.
Choose The Stack Based On Privacy, Cost, And Operational Needs
The right stack depends on constraints. A healthcare or legal workflow may prioritize privacy, auditability, and controlled retrieval. A public support bot may prioritize response speed, source freshness, and easy content updates. An internal engineering assistant may prioritize code/document search, permissions, and integration with development tools.
Use a simple decision rule: prototype locally when the main uncertainty is retrieval quality; deploy to cloud when the main requirement is shared reliable use. For regulated or sensitive workflows, add security and governance review before expanding the user base. NIST’s AI Risk Management Framework resources are a useful starting point for identifying generative AI risks such as privacy, information integrity, and security.
What Breaks In Real RAG Chatbots
Real RAG chatbots usually fail in predictable places: bad source data, weak chunks, stale indexes, vague queries, slow inference, missing access control, and unmeasured answer quality. Teams should design test cases for these failures before launch.
Empty Or Low-Quality Answers
Empty answers happen when retrieval returns no useful context or when the prompt is too strict for the available data. Low-quality answers happen when the model receives weak context and tries to sound helpful anyway. The fix starts with retrieval inspection: log the query, retrieved chunks, scores, metadata filters, final prompt, and final answer.
Teams should build a small evaluation set of real questions and expected source documents. If the correct document does not appear in the top results, adjust parsing, chunking, metadata, hybrid search, or reranking before blaming the model.
Wrong Chunks Or Stale Indexes
Wrong chunks usually come from poor splitting, missing metadata, duplicate pages, or retrieval that ignores source structure. Stale indexes happen when source documents change but the vector store does not refresh. Both failures can produce confident but outdated answers.
A production ingestion pipeline should track source IDs, content hashes, timestamps, owners, and deletion status. When a document changes, the system should update or remove the related chunks. A chatbot that keeps deleted policy text in its index can become a compliance problem.
Slow Inference And Vague Queries
Latency comes from several places: document retrieval, reranking, LLM generation, network calls, and UI streaming. A RAG chatbot may feel slow if it retrieves too many chunks, uses a large model for every request, or performs unnecessary multi-step calls.
Vague queries are another common source of bad answers. A user may ask “What is the policy?” without naming the product, region, or user role. The chatbot should ask a clarifying question when the query is underspecified instead of retrieving random policy chunks.
Dependency Or Framework Deprecations
RAG frameworks move quickly. LangChain, LlamaIndex, model APIs, vector stores, and cloud services can change methods, packages, pricing, and recommended patterns. A prototype copied from an old tutorial may break after package upgrades or API changes.
Production teams should pin dependencies, read changelogs, write integration tests, and keep a migration path. A RAG chatbot is an application, not a notebook. Treat framework upgrades like product releases with regression testing and rollback plans.
What Production-Ready RAG Chatbots Need
A production-ready RAG chatbot needs measurable retrieval quality, trusted citations, secure access, observability, and maintainable integration across UI, backend, model provider, and vector store. The checklist below is a practical launch gate.
Production readiness stack
The readiness stack shows why a working demo is only the base layer. Production teams need trust, quality, security, and data operations around the core RAG architecture before users rely on the chatbot.
- Retrieval accuracy and indexing quality. Test whether the correct chunks appear for real user questions before evaluating generated answers.
- Source citations and trust controls. Show source titles, sections, links, or snippets so users can verify important answers.
- Security, controlled access, and privacy-aware retrieval. Filter retrieval by user role, workspace, customer, region, or document permission before the LLM sees the context.
- Observability, evaluation, and feedback loops. Track retrieval results, answer quality, latency, cost, and user feedback over time.
- Integration across UI, backend, and vector store. Make ingestion, retrieval, generation, source display, and error handling part of one tested workflow.
Evaluation should measure both retrieval and generation. Ragas, for example, lists metrics for RAG workflows, including context precision and related quality checks in its RAG evaluation metrics documentation. Teams can also build simpler internal rubrics, such as whether the answer uses the correct source, avoids unsupported claims, cites the right document, and escalates when context is missing.
A launch scorecard should test retrieval and generation separately. The chatbot can only be trusted when the system finds the right evidence and the answer stays faithful to that evidence.
| Quality area | Pass signal | Failure signal | Owner |
|---|---|---|---|
| Retrieval accuracy | Expected source appears in the top retrieved chunks for real questions. | The answer is wrong because the system retrieved unrelated or outdated chunks. | AI engineer / search engineer |
| Citation faithfulness | The answer?s claim can be traced to the displayed source section. | The citation points to a source that does not support the answer. | QA / domain reviewer |
| Permission safety | The retriever filters by user role, workspace, customer, or region before context reaches the LLM. | A user can retrieve content from a forbidden project, client, or internal folder. | Backend / security owner |
| Fallback behavior | The chatbot says it does not know, asks a clarifying question, or escalates when context is missing. | The chatbot fills gaps with a confident unsupported answer. | Product owner / AI engineer |
| Operational health | Logs show latency, cost, failed retrievals, unanswered questions, and feedback trends. | The team cannot explain why answer quality changed after a source, prompt, model, or package update. | DevOps / product analytics |
Designveloper helps teams build AI chatbots and RAG systems by connecting product discovery, data workflow design, software architecture, UI development, testing, deployment, observability, and post-launch iteration. For teams planning a production assistant, our RAG best practices guide, LangChain RAG guide, and AI development services explain the broader delivery context around secure, grounded AI applications.
FAQs About Building A RAG Chatbot
The questions below cover the decisions teams usually face after a prototype starts answering basic questions.
How Does RAG Reduce Hallucinations?
RAG reduces hallucinations by giving the model retrieved source context before generation. The model has a better chance of answering correctly when the right policy, document section, or knowledge-base article is included in the prompt. RAG does not eliminate hallucinations by itself, because the chatbot can still retrieve weak context or ignore instructions. Strong RAG systems combine retrieval tests, strict prompting, citations, and fallback behavior for insufficient context.
Can A RAG Chatbot Work With Local Or Open-Source LLMs?
A RAG chatbot can work with local or open-source LLMs if the hardware, latency, quality, and maintenance requirements fit the use case. Local models are useful for private prototypes, offline experiments, and cost-controlled internal tools. Managed cloud models may perform better for complex reasoning, multilingual support, uptime, and scaling. The retrieval design is still important in both cases.
What Data Sources Work Best For RAG?
The best data sources for RAG are authoritative, current, well-structured, and permission-aware. Help-center articles, technical documentation, policies, SOPs, product specs, manuals, internal knowledge bases, and curated PDFs often work well. Messy document dumps, duplicate exports, outdated folders, and unreviewed chat logs create retrieval problems. If source quality is weak, fix the source pipeline before tuning the model.
Do I Need Cloud Services To Build A RAG Chatbot?
Cloud services are not required for a local RAG chatbot prototype. A developer can run parsing, embeddings, vector storage, retrieval, and an LLM locally or on a private server. Cloud services become more useful when multiple users need access, documents must refresh automatically, uptime matters, or the chatbot needs authentication, monitoring, and scalable deployment.
How Do Teams Measure RAG Chatbot Quality?
Teams measure RAG chatbot quality by testing retrieval accuracy, answer faithfulness, citation correctness, response usefulness, latency, cost, and user feedback. A good evaluation set includes real user questions, expected source documents, acceptable answer criteria, and edge cases where the chatbot should say it does not know. Production teams should review quality continuously because source content, user behavior, model behavior, and framework dependencies change over time.
Also published on

Share post on










Related Articles

How To Build An AI Chatbot With Long-Term Memory? (2026 Guide)
How To Build An AI Chatbot With Long-Term Memory? (2026 Guide) Published June 25, 2026
Why Developers Say LangChain Is “Bad”: An Honest Look At LangChain
Why Developers Say LangChain Is “Bad”: An Honest Look At LangChain Published June 23, 2026
How To Build A RAG System: Step-By-Step (New Guide)
How To Build A RAG System: Step-By-Step (New Guide) Published June 23, 2026





















