














RAG, short for Retrieval-Augmented Generation, is one of the emerging techniques receiving much attention from the developer community. It is considered an effective way to improve the natural capabilities of LLMs and make them work better in response generation. In our previous article, we detailed what RAG is and how it works. So now we want to further explain the RAG pipeline diagram, along with its key components and how you can build a seamless RAG pipeline.
What is a RAG Pipeline Diagram?
A RAG pipeline diagram is a visual flowchart that shows how a RAG (Retrieval-Augmented Generation) technique is integrated into LLMs (Large Language Models) to enhance their capabilities.
In other words, the diagram visualizes how retrieval and generation work together to generate more accurate, relevant, and contextual responses by combining both a user’s query and retrieved information. It starts with receiving the user’s request and processing external databases to find the most relevant documents and retrieve the most essential information. All occur behind the scenes, where users hardly see with their naked eyes.
The RAG pipeline diagram consists of a sequence of boxes and arrows connecting them. Below is a typical pipeline:
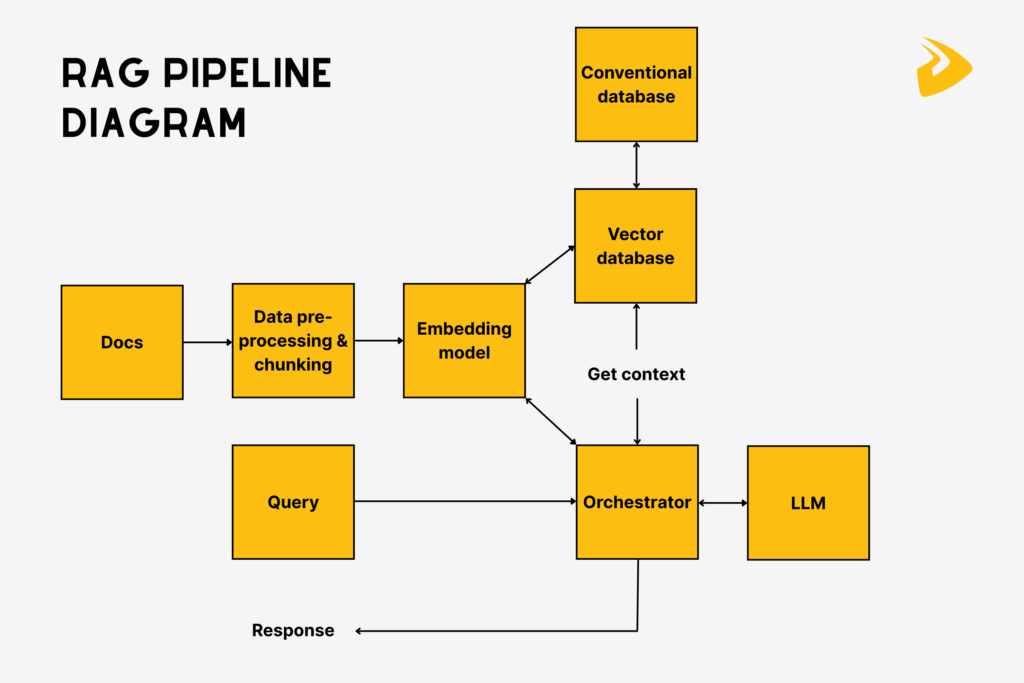
Key Components of RAG Pipeline Diagram
To help you better understand a RAG pipeline diagram, we now explain each of its components displayed in the figure above:
Documents & Data Sources
The first component of the diagram is defined data sources, which offer raw data for the LLM to create fact-based, personalized responses. These sources can be policy documents, databases, support tickets, PDFs, etc. They often contain domain-specific data that the LLM doesn’t have. The quality and integrity of this data significantly affect the accuracy of LLM-generated outputs.
For example, a customer asks about your service’s pricing plans. If these data sources haven’t yet updated your new pricing packages, the LLM still provides incorrect and outdated responses. So, it’s crucial to ensure that what you give the LLM is complete, accurate, relevant, and up-to-date.
Data Pre-processing & Intelligent Chunking (JSON or Other Formats)
External sources often have unstructured or semi-structured data. To pre-process it for the LLM to interpret correctly, developers often leverage pre-processing tools like LangChain’s document loaders. These loaders aim to load different content from multiple data sources and convert it into a standard data format like JSON.
Next, this data is broken down into small, contextually meaningful pieces of text (“chunks”). This process, often known as “chunking,” is crucial as retrieval systems and embedding models have context window limits. In other words, they can’t handle the entire content of a long document at once. That’s why chunking will help these systems absorb each content piece better.
There are many chunking strategies to adopt, like fixed-size chunking, recursive chunking, or semantic chunking. Your strategy choice depends much on the types of documents and use cases. For example, fixed-size chunking is used if the content of external datasets has similar formats and sizes (e.g., blog posts or news articles). Regardless of your choice, remember the key details as follows:
– Chunks should be semantically coherent instead of being randomly split.
– Keep some overlap between chunks so that the context can’t be lost when documents are chunked.
– Build a hierarchical structure that shows parent-child relationships between chunks for easier retrieval and better context.
– Keep metadata (title, source, date) for each chunk to support citations and filtering later.
– Preserve formats (bullet points, tables, etc.) to keep the meaning and readability of the content intact.
– Maintain links between related chunks to ensure a full understanding of the context.
Embedding Models
Embedding models are systems that convert each chunk of data into vector representations or embeddings (”numeric formats”). They’re also used to embed a user query, so that retrieval systems can compare the numeric vectors (“embeddings”) of both the query and the stored documents to identify the most relevant chunks.
These embedding models don’t look for the same words, but capture semantic meaning and perform similarity searches. For example, if a user asks about “how to get refunds,” the system can extract sections about “refund policies” as their embeddings are close in a vector space.
Vector Databases & Conventional Databases
Those embeddings are stored and indexed in a specialized database, known as a vector store. Unlike traditional databases that process row-and-column data, vector stores excel at handling high-dimensional vectors and performing similarity searches swiftly. Some common vector databases include Milvus, Pinecone, and Weaviate.
If external sources contain structured data, it’ll often be stored in conventional databases, like MySQL or PostgreSQL. This data, which includes document links, metadata, and other relational information, doesn’t need semantic embeddings, as you can match them directly by value. Accordingly, you just need to run traditional queries, like filtering by specific attributes or fields for exact searches.
User Query Processing
User query is a user’s input questions or prompts using natural language. Similar to external documents, a user’s query is converted into a vector using an embedding model so that the system can understand what the user wants. The original query and the retrieved information are fused into a single prompt and passed to the generator (LLM).
Orchestrator
When you look around RAG pipeline diagrams developed by various companies, you may not see this component: Orchestrator. Although it doesn’t do heavy lifting like others, we can’t deny its important role as a “project manager” in a RAG pipeline.
In particular, an orchestrator ensures seamless communication between components and supports the sequence of operations, from query management and data retrieval to interaction with the LLM. This ensures the right components are used at the right time and in the right order, helping the RAG pipeline avoid a messy tangle.
Large Language Models (LLMs)
LLM, short for Large Language Models, essentially acts as a generation component in a RAG pipeline diagram. It’s often trained on vast amounts of data, serving general purposes, from learning a new language to drafting a report. The integration of RAG allows LLM-based applications to receive updated, context-aware information in real time. Accordingly, LLM can generate factual, contextually relevant responses for a user’s query. This increases customer satisfaction and also reduces hallucination – a common problem of existing LLMs.
Benefits of Using a RAG Pipeline Diagram

So, why do you need a RAG pipeline diagram? This section will clarify several benefits of using a diagram in designing a RAG-powered system:
Have a clear visualization of workflows
First, a RAG pipeline diagram visualizes how data flows through the system. This allows you to see the process step by step instead of only looking at abstract descriptions or code lines. For this reason, developers and even non-technical people can understand the workflow without getting lost in technical details.
Identify optimization spots
When you look at a visual representation of a RAG system, you can quickly detect where to improve its performance. In other words, you can easily spot which steps use resources inefficiently, repeat unnecessary actions, or take too long. This allows you to refine the RAG system more quickly and effectively.
Troubleshoot issues
The RAG pipeline diagram functions as a clear roadmap for troubleshooting the issues that occur in the system. Accordingly, you can trace the problems back to their source and identify which steps are failing, instead of guessing where the issues come from in the code. This helps you save time in troubleshooting.
Design a RAG system effectively
With a RAG pipeline diagram, you can better envision the potential system in a logical, organized way. This supports you in designing and building a system that aligns with your business’s requirements. Accordingly, you can experiment with different structures and add components that benefit your workflows. This mitigates the risk of building an inefficient or hard-to-maintain system.
How the RAG Pipeline Works (Step-by-Step Workflow)
So, how does the RAG pipeline work? This section will detail each step of the RAG pipeline to help you better envision how the RAG technique helps generate a contextually grounded, coherent, and personalized answer based on a user query.
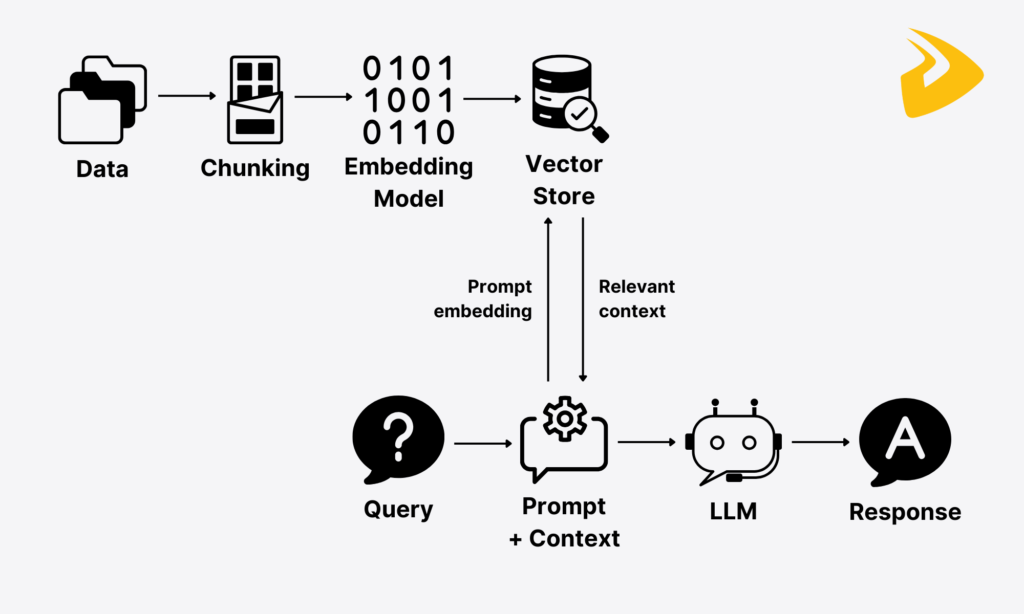
Data Ingestion
Our RAG pipeline starts with data ingestion. This phase refers to allowing the RAG system to access and absorb raw data from external knowledge bases, regardless of data types and formats. The raw data here is mostly unstructured or semi-structured, such as social media posts, product descriptions, research articles, or customer reviews.
Normally, you can pull the data from any external sources through document loaders, such as LangChain’s WebBaseLoader or LlamaIndex’s SimpleDirectoryReader. These document loaders help pre-process the data by structuring it in a standard format like JSON.
Document Indexing
Once the RAG pipeline ingests raw data, the system will break it down into smaller chunks of text. This step is crucial as the system can only handle a limited amount of text (often measured in “tokens”) at the same time. Therefore, chunking long documents helps avoid overwhelming the system and ensures smooth data processing later.
Embedding Generation
Next, those chunks of data will be transformed into vector representations or embeddings. These embeddings will encode the meaning of textual data into numerical formats so that the system can read and interpret. This step is performed by using the embedding models, like OpenAIEmbedding, AzureOpenAIEmbeddings, or AWS’s BedrockEmbeddings, available in open-source frameworks (e.g., LangChain or LlamaIndex).
Data Storage in Vector Databases
Afterwards, these embeddings are stored in vector stores/databases for easy semantic search and retrieval later.
Querying and Retrieval
When a user sends a query, this query is also converted into embeddings for similarity search. In particular, the system will compare the embeddings of both the query and the stored information to calculate how relevant they are. This allows the system to find the top N chunks (which means the first batch of the most relevant chunks). In some applications, like in the case of Pinterest, the system will further narrow the chunks down into the top K information and then fuse it to an LLM prompt for response generation.
Augmented Generation With LLM
The final step of the RAG pipeline diagram is to combine the given query and the retrieved information into the LLM prompt, which guides how the LLM should behave. Open-source frameworks, like LangChain or LlamaIndex, offer built-in prompt templates, so you don’t need to create one from scratch. Through this augmentation prompt, the LLM will return a factually accurate, contextually coherent, and personalized answer to the given query.
How to Build the RAG Pipeline for Beginners?
Are you finding ways to create your own from scratch? If you’re new to the RAG pipeline, follow the detailed steps in this section to build a simple RAG pipeline:
Setting Up the Environment
One crucial step you need to complete before building a RAG pipeline is to prepare your development environment. Set up at least Python 3.9+ and a package manager like `pip`. Further, you need the following important libraries:
- LangChain or LlamaIndex to create RAG pipelines
- Pinecone, FAISS, or Weaviate to store embeddings
- Transformers from, for example, Hugging Face for embeddings and model loading
- dotenv to manage API keys securely
Example:
pip install langchain langchain-openai openai faiss-cpu tiktoken python-dotenv
Ensure to store your API keys in a .env file for security.
import os
from dotenv import load_dotenv
load_dotenv()
OPENAI_API_KEY = os.getenv(“OPENAI_API_KEY”)
os.environ[“OPENAI_API_KEY”] = OPENAI_API_KEY
Choosing the LLM and Embedding Model
Now, you need to select and install two core components for your RAG system:
- LLM: Generates final responses enriched with retrieved context. Some common options are GPT-3.5 turbo, GPT-4, or open-source models like LLaMA 2.
- Embedding Model: Turn textual data into numerical vectors for semantic search. Some popular choices include text-embedding-ada-002 (OpenAI) or sentence-transformers/all-MiniLM-L6-v2.
Tips for beginners: Select a managed API like OpenAI to avoid handling heavy local deployments.
Example:
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
# Embedding model
embeddings = OpenAIEmbeddings(model=”text-embedding-ada-002″)
# LLM (you can switch to gpt-4 if available)
llm = ChatOpenAI(model=”gpt-3.5-turbo”, temperature=0)
Preparing and Chunking Data
The RAG system works best if your data is structured in a standardized format. So, start by collecting your domain-specific, valuable documents (e.g., web pages, text files, or PDFs). Then, clean them by eliminating irrelevant sections, unnecessary symbols, or extra spaces. Next, you should break documents down into smaller chunks (for example, 100-200 tokens for small demos, while 300-500 tokens for real-world scenarios). This aligns each chunk with the model’s context window and boosts retrieval accuracy.
Example:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document
# Sample text
raw_text = “””
LangChain is a framework for developing applications powered by large language models.
It provides tools for prompt management, chaining, memory, and integration with data sources.
“””
# Convert to LangChain Document
docs = [Document(page_content=raw_text)]
# Split into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
documents = splitter.split_documents(docs)
print(documents[0].page_content)
Prompt Engineering
Prompt engineering is a crucial step to help the LLM identify exactly how to use retrieved information and generate a response. A basic RAG prompt often includes the user’s query, retrieved context chunks, and clear instructions to base answers on the provided context. In production, use ChatPromptTemplate for chat models to separate system/user instructions. So here’s an example you can refer to:
from langchain.prompts import PromptTemplate
# Template that inserts retrieved context
prompt_template = “””
You are a helpful assistant. Use the following context to answer the question.
Context: {context}
Question: {question}
Answer:
“””
qa_prompt = PromptTemplate(
input_variables=[“context”, “question”],
template=prompt_template,
)
Creating the Query Engine
The basic query engine often includes a retrieval system and a vector store. Its goal is to fetch relevant data from your vector store or database. Efficient retrieval often includes the following steps:
- Convert a user query into an embedding
- Search the vector stores for relevant chunks
- Pass the retrieved context and the query to the LLM
Example:
from langchain.vectorstores import FAISS
# Create vector store
vectorstore = FAISS.from_documents(documents, embeddings)
# Function to fetch relevant documents
def retrieve_context(query, k=3):
docs = vectorstore.similarity_search(query, k=k)
return “\n”.join([d.page_content for d in docs])
Running the Pipeline
When you already have all the essential ingredients and instructions, the final step is to integrate all the steps above into a single flow.
Example:
def rag_pipeline(question):
# Step 1: Retrieve context
context = retrieve_context(question)
# Step 2: Format the prompt
prompt = qa_prompt.format(context=context, question=question)
# Step 3: Get LLM response
response = llm.invoke(prompt)
return response
# Test the pipeline
print(rag_pipeline(“What is LangChain used for?”))
Output (Example):
LangChain is a framework that helps developers build applications powered by large language models. It offers tools for managing prompts, chaining operations, memory handling, and integrating with different data sources.
Note: The response may vary slightly because LLMs are non-deterministic, even with temperature=0
This RAG pipeline can be expanded later with advanced capabilities, like caching results for faster responses, adding various data sources, or using re-ranking to enhance retrieval quality.
Why Does the RAG Pipeline Matter for LLM Applications?

As we all know, LLMs (Large Language Models) are powerful and beneficial. But they still have some natural limitations. In particular, they are trained on fixed datasets, which have a cut-off date, but they cannot proactively update every new piece of information. This limitation makes LLMs create outdated or hallucinated responses. This is a big challenge in areas where the information continuously evolves and factually grounded responses are paramount. That’s why a RAG pipeline comes in and makes a real difference.
The RAG pipeline will connect an LLM to external data sources (like databases, APIs, and documents). Instead of depending only on its training data, the RAG-powered model can retrieve relevant, latest information and inject the context into its prompt. This allows the model to give factually grounded and contextually aware answers, rather than just guessing.
The benefits of RAG go beyond accuracy. It allows your business to access real-time knowledge by pulling fresh data from external knowledge bases to keep outputs relevant. Additionally, it can handle domain-specific tasks effectively by fusing your private or proprietary data into the pipeline. Also, it enhances operational efficiency and cost savings. Instead of adjusting the model repeatedly, which requires a big investment, you can simply update the external data sources and let the system retrieve relevant information from them.
How Designveloper Helps Your Business Build an Effective RAG App

If you want to build a RAG pipeline and need expert help, Designveloper is a perfect partner in your RAG journey. With in-depth technical expertise in 50+ modern technologies, our highly skilled developers excel at developing custom, scalable solutions for clients across industries, from finance and education to healthcare. We also make an active investment in integrating emerging tools, like LangChain, Rasa, AutoGen, and CrewAI, to deliver reliable solutions that help our clients stay ahead of the competition.
Here at Designveloper, we have been experimenting with RAG techniques in Lumin. This is a document platform that enables users to view, edit, and share PDF documents smoothly. It integrates with cloud storage services to facilitate access and collaboration on documents, wherever users live. The integration of RAG is expected to enhance Lumin’s capabilities by allowing users to query and interact with their documents using natural language. This will simplify complex PDF editing tasks and reduce difficulties in real-time document collaboration.
With our flexible Agile process and dedication to high-quality results, we commit to delivering every project on time and within budget. So, don’t hesitate to contact us and discuss your idea further! Our extensive expertise and long-term experience help turn your idea into working solutions!
Also published on

Share post on










Read more topics










You may also like

7 Key Differences Between Agentic AI vs Generative AI (GenAI)
7 Key Differences Between Agentic AI vs Generative AI (GenAI) Published February 10, 2026
What Is Agentic AI? Benefits, Architecture and How It Works
What Is Agentic AI? Benefits, Architecture and How It Works Published February 10, 2026
10+ Best Vibe Coding Tools for Beginners in 2026
10+ Best Vibe Coding Tools for Beginners in 2026 Published December 25, 2025











