












What Is MLOps? Understanding MLOps Lifecycle and How It Works
Modern machine learning systems touch almost every business function today. Models rank search results, score credit risk, route support tickets, and power chatbots. Yet many organizations still struggle to turn promising prototypes into reliable products. This relates crucially to the question “what is mlops”.
Leaders invest heavily in AI, but value often lags. The global MLOps market alone is forecast to reach USD 16,613.4 million by 2030, which shows how urgent the need for robust operations has become worldwide. At the same time, enterprise AI adoption keeps rising; one global survey found that 78 percent of respondents say their organizations use AI in at least one business function, so operational gaps now matter at real scale.
Against this backdrop, many teams still type “what is mlops ” into a search bar when their first models start failing in production. This article gives a clear and practical answer. It explains what MLOps is, how the lifecycle works, the maturity levels, and the main benefits and challenges. You will also see concrete examples, tools, and fresh data points from recent industry reports.
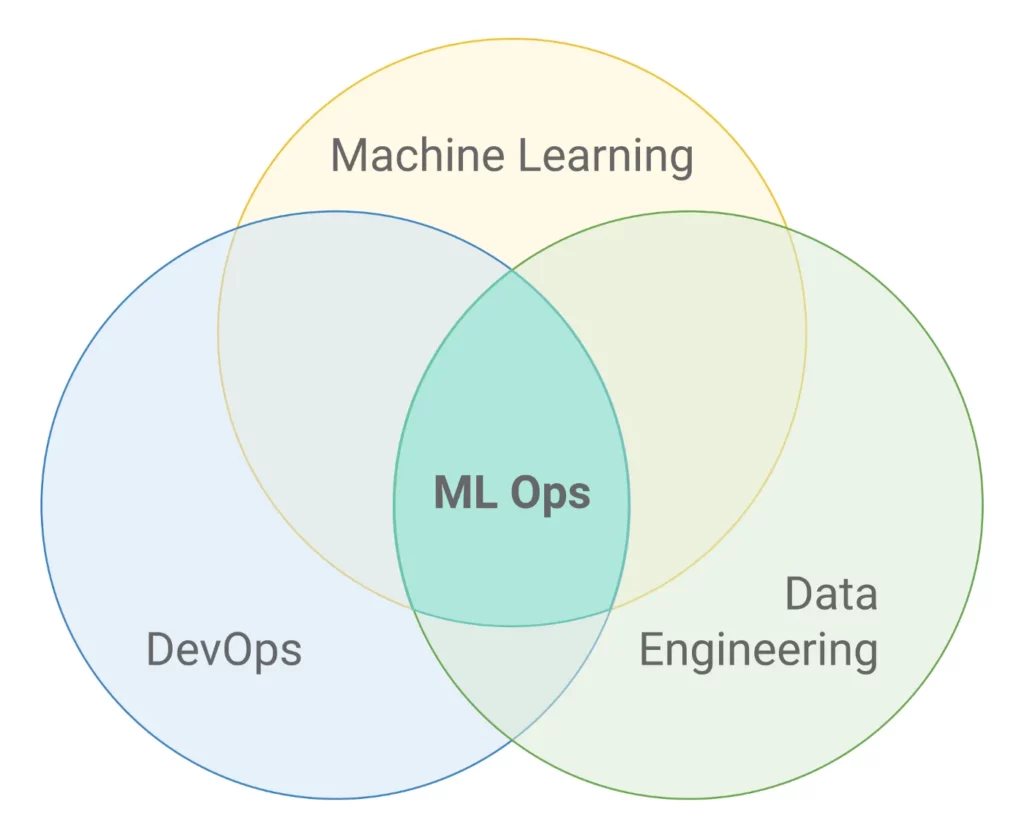
What Is MLOps?
This section explains the core idea of MLOps and why it matters now. It also compares MLOps with traditional DevOps and describes the pain points that led to its rise.
At its core, MLOps is an engineering discipline. It combines machine learning, software engineering, and operations to manage the full lifecycle of ML models in production. IBM describes MLOps as a set of practices that streamline model creation, deployment, monitoring, and governance so that models stay accurate, scalable, and well controlled over time, rather than just during experiments in a lab. You can think of it as applying mature DevOps ideas to the unique needs of data and models.
Many teams ask “what is MLOps?” only after their first production model breaks. A data scientist may have trained a strong model in a notebook. The team then ships it as a one-off script. Over time, input data drifts, traffic grows, and infrastructure changes. No one owns monitoring or retraining. Performance degrades, and trust erodes. MLOps exists to prevent this slow failure by treating models as long-lived products with structured workflows.
In short, MLOps answers a simple question: how do we build, deploy, and maintain ML systems with the same rigor we expect from any critical software system, while still respecting the unique behavior of data-driven models?
Core Components of the MLOps Lifecycle
The MLOps lifecycle spans several tightly linked components. Each component tackles a different risk: data quality, model quality, operational stability, and compliance. Together, they create a repeatable path from raw data to reliable predictions.
1. Data Management
Data management is the foundation of any MLOps practice. If data is wrong, late, or inconsistent, even the best model will fail. So MLOps teams treat data pipelines as first-class products, not afterthoughts.
Effective data management in MLOps usually includes four elements. First, teams define reliable data ingestion from source systems such as transaction databases, event streams, and external APIs. Second, they enforce data validation rules, such as schema checks, range checks, and null handling. Third, they version datasets and features, so any model version can be traced back to the exact data that trained it. Finally, they secure sensitive fields and apply anonymization where needed.
Many organizations adopt a feature store to support this work. A feature store is a central service that stores curated features with metadata, access controls, and both batch and real-time read paths. It lets data scientists reuse features across projects and ensures training and serving use the same definitions. Platforms like Feast, Tecton, and cloud-native stores inside Vertex AI or SageMaker are common, but even a well-managed warehouse table can serve as a lightweight feature store if teams apply clear conventions.
Good data management also covers lineage and documentation. MLOps teams often track which upstream jobs created each feature, which alerts fire when quality drops, and which business owners own each domain. This level of traceability helps during audits and speeds up incident response when something goes wrong.
2. Model Development
Model development in MLOps still includes classic tasks like feature engineering, model selection, and hyperparameter tuning. The difference lies in how teams structure the work. Instead of ad hoc notebooks that never leave a laptop, MLOps encourages reproducible pipelines and experiment tracking from day one.
Teams usually start with notebooks for exploration. Once a promising approach appears, they refactor core logic into modules or pipeline steps. Tools like MLflow help track runs, parameters, metrics, and artifacts. Frameworks such as PyTorch Lightning add structured training loops, callbacks, and logging, which makes it easier to standardize training code across projects.
An MLOps-friendly model training process has a few traits. Training scripts read configuration from files rather than hard-coded values. Data splits and evaluation metrics follow shared templates. Experiment runs log enough metadata to reproduce any result later. Model artifacts, such as serialized weights and preprocessing logic, move into a model registry where they receive version numbers and status labels like “staging” or “production.”
This discipline lets teams answer simple but crucial questions. Which model version is live right now? What about the data slice it performs poorly on? Which hyperparameters produced that improvement last quarter? Strong model development practices make those answers easy.
3. Model Deployment
Model deployment turns a trained model into a usable service, batch job, or embedded component. Here, MLOps borrows heavily from DevOps, especially around containerization and orchestration.
Most modern teams package models and serving code into Docker images. The image includes all necessary libraries, runtime dependencies, and model files. This approach avoids the classic “works on my laptop” problem and simplifies promotion across environments.
For online use cases, Kubernetes or similar orchestrators run these containers as scalable services. An API gateway or load balancer routes prediction requests to the right pods. MLOps practices then add deployment patterns like blue–green releases, canary rollouts, and shadow testing. For example, you might deploy a new model as a shadow service that receives real traffic but does not affect user-facing decisions until it proves stable.
For batch use cases, deployment may mean scheduled jobs on a data platform. A churn model, for instance, might run nightly in a Spark job, write scores to a warehouse, and trigger email campaigns. MLOps still applies here: jobs use versioned code, declarative configs, and automated validation, and teams maintain clear rollback procedures.
4. Model Monitoring
Once a model is live, monitoring becomes the heartbeat of MLOps. Without it, teams fly blind. Monitoring covers both technical health and business performance.
On the technical side, MLOps teams watch latency, error rates, throughput, and infrastructure metrics. Tools from the DevOps world, such as Prometheus, Grafana, OpenTelemetry, and cloud-native monitoring stacks, still work well here.
On the ML side, monitoring also tracks prediction quality, data drift, and bias. Teams compare input distributions to training data, watch changes in label distributions, and evaluate accuracy or calibration when ground truth arrives. They often build dashboards for key segments, such as high-value customers or specific geographies, so they can see localized issues early.
Weak monitoring remains a real problem in industry. A recent survey in India reported that About 81% of Indian enterprises do not have effective tracking and monitoring for artificial intelligence systems, even as they roll out more AI use cases. That gap directly raises operational and security risk. Strong MLOps practices seek to close it through standard monitoring templates, alert runbooks, and ownership models.
5. Model Governance
Model governance ensures that ML systems stay compliant, ethical, and accountable. It spans permissions, approvals, documentation, and risk controls across the lifecycle. As regulations tighten, this component moves from “nice to have” to mandatory.
Effective governance usually starts with a model registry that stores metadata like owners, intended use, training datasets, evaluation results, and approval status. Access controls restrict who can promote a model to production or change its configuration. Review boards, often including legal and risk teams, may need to sign off on models that affect credit, hiring, healthcare, or safety.
Governance also ties back to monitoring. Many organizations define guardrail metrics, such as minimum accuracy thresholds, fairness constraints, or maximum defect rates. If a metric crosses a boundary, the monitoring system can trigger alerts, rollbacks, or retraining workflows. Audit trails then record who acted and what changed.
IBM highlights governance and scalability as core outcomes of MLOps, noting that structured practices help ensure consistency, reproducibility, and policy compliance across models, rather than leaving each team to improvise controls. That consistency becomes crucial as the number of models in production grows.

How Does MLOps Work? The MLOps Pipeline
MLOps comes to life through concrete pipelines.
Step 1: Data ingestion and feature engineering. The pipeline begins by pulling data from operational systems, logs, data warehouses, or event streams. Ingestion jobs clean and normalize records, handle missing values, and enforce schemas. Next, feature engineering transforms raw fields into meaningful signals: aggregated counts, time-based trends, embeddings, or domain-specific scores. These transformations should live in reusable code, not one-off notebooks.
Step 2: Model training and validation (MLflow, PyTorch Lightning). Once features are ready, the pipeline launches training jobs. With PyTorch Lightning or similar frameworks, training code stays modular and consistent, while MLflow or comparable tools track experiments. The pipeline may run multiple model candidates in parallel, varying architectures or hyperparameters. Validation then uses holdout or cross-validation splits to check performance on representative data. The pipeline logs metrics like AUC, precision, recall, calibration, and business KPIs. Only candidates that meet predefined thresholds move forward to packaging.
Step 3: Model packaging and deployment (Docker, Kubernetes). For deployment, the selected model and its preprocessing logic move into a standardized serving image. Docker provides the container format, while build tools bake in the exact library versions and system dependencies. A CI system then runs automated tests, security scans, and contract checks on this image. If checks pass, the pipeline can push the image to a registry and deploy it onto Kubernetes or another orchestrator.
Step 4: Continuous monitoring, feedback loop, auto retraining. After deployment, monitoring jobs analyze logs, metrics, and feedback signals. If they detect data drift, performance decay, or new failure modes, they can trigger a new training run. In advanced setups, pipelines implement continuous training, where fresh data automatically flows into retraining jobs based on triggers defined in tools such as Kubeflow Pipelines or cloud-native orchestrators.
Levels of MLOps
Not every organization needs the most advanced MLOps setup on day one. Google Cloud’s view of MLOps maturity levels provides a helpful roadmap, from fully manual work to integrated CI/CD pipelines. We can extend that idea to describe four practical levels: from no MLOps to advanced practices.
1. Level 0: No MLOps – Manual Process
At Level 0, teams run ML projects through manual scripts and informal steps. A data scientist might query data in a notebook, train a model locally, export a file, and send it to an engineer by email or chat. The engineer then wraps the file in a simple service or batch job.
There is little or no automation at this level. Retraining happens only when someone remembers to do it. Data validation rarely exists. Model versions may be buried on laptops or in ad hoc folders. Debugging issues across environments becomes painful, because no one captured exact dependencies or data snapshots.
This level may work for small, low-risk experiments. However, it cannot scale. When an organization starts to run many models at once, manual processes quickly lead to outages, embarrassing bugs, and duplicated work.
2. Level 1: ML Pipeline Automation
Level 1 introduces automated ML pipelines but still keeps CI/CD for code separate. Here, teams define training workflows as pipelines that run in a scheduler or orchestrator. The pipeline automates data ingestion, feature preparation, training, evaluation, and model registration.
At this level, new data can trigger retraining automatically, either on a schedule or based on events. Data and model validation steps run inside the pipeline to prevent bad inputs from poisoning models. Metadata stores record runs, artifacts, and metrics, so teams can compare versions and reproduce results. Google Cloud’s MLOps guidance highlights continuous training at this level, where models update frequently as new data arrives.
However, Level 1 often still lacks tight integration between model pipelines and broader software delivery. Application teams may still deploy models manually into their systems, and changes to model code may not flow through a unified CI/CD process.
3. Level 2: CI/CD Pipeline Integration
At Level 2, organizations integrate ML pipelines into the same CI/CD systems that manage application code. Source control, build services, test suites, and deployment automation handle both models and traditional software components.
When a data scientist or ML engineer commits a change, the CI pipeline runs unit tests for data transformations and model code. It also builds and tests container images that include the training or serving logic. Successful builds trigger deployments of pipelines and services into staging and then production, with automated rollbacks on failure.
This level tightens feedback loops across teams. Engineers, analysts, and operations staff gain a shared view of artifacts, environments, and deployment history. It also improves traceability, since the same systems log changes to both code and models.
4. Level 3: Advanced MLOps
Level 3 represents advanced MLOps practices that large or highly regulated organizations often pursue. Here, automation, monitoring, and governance cover the entire ML ecosystem, from data ingestion to downstream business processes.
In advanced MLOps setups, model training and deployment pipelines integrate with enterprise data catalogs, access-control systems, and risk workflows. Feature stores and model registries share common identity and audit logs. Teams implement automated drift detection with clear playbooks that balance auto retraining and human approval. Rollouts often use sophisticated strategies such as multi-armed bandits or reinforcement learning to allocate traffic between model variants.
Advanced organizations also extend MLOps to generative AI systems, vector databases, and retrieval-augmented generation pipelines. They track prompts, retrieved documents, and generated outputs alongside traditional metrics. Governance covers prompt templates, safety filters, and response review processes. At this level, MLOps becomes part of a broader AI platform strategy, not just an isolated set of tools.

Benefits of MLOps
Done well, MLOps delivers clear business benefits. It reduces waste, speeds delivery, and increases trust in AI systems. It also helps organizations move from scattered experiments to sustainable, value-generating products.
First, MLOps improves operational efficiency. Automated pipelines, standardized tooling, and shared platforms cut the time engineers spend on repetitive tasks. An Expert Market Research report notes that by using MLOps, organisations can enhance their process efficiency by 30%, thanks to streamlined workflows and better reuse. That gain shows up as faster rollouts, fewer manual fixes, and more time for high-value experimentation.
Second, MLOps improves model quality. Continuous evaluation, drift detection, and structured retraining help models stay accurate as conditions change. For example, a fraud model might see new attack patterns or shifts in customer behavior.
Third, MLOps strengthens collaboration between data scientists, engineers, and operations teams. Shared pipelines, registries, and dashboards create a common language. Data scientists can focus on model logic, knowing that deployment follows stable patterns.
Fourth, MLOps supports compliance and risk management. Centralized model governance, documentation, and audit logs help organizations meet regulatory expectations in finance, healthcare, and other regulated sectors.
Finally, MLOps helps organizations close the gap between AI hype and real value. With structured operations, models make it into production more often and stay useful longer. This longitudinal impact matters more than any single benchmark win.
Challenges When Implementing MLOps
Despite its benefits, implementing MLOps is not trivial. Many organizations underestimate the cultural, technical, and governance changes required. Understanding common challenges helps leaders plan realistic roadmaps.
One major challenge is organizational culture and skills. Traditional data science teams may be comfortable working in isolated notebooks, while platform teams think mainly in terms of microservices and infrastructure.
Another challenge is tool sprawl. The MLOps ecosystem includes many overlapping products for experiment tracking, orchestration, feature storage, model serving, and monitoring. Teams may adopt multiple tools without a clear architecture, creating new silos instead of reducing them.
Data quality and accessibility also pose obstacles. MLOps cannot fix broken upstream data on its own. If source systems lack stable identifiers, timestamps, or consistent semantics, pipelines will remain fragile. Many companies must first invest in data engineering and governance before they can reap the full benefits of MLOps.
Governance and security form another pressure point. The Indian survey mentioned earlier shows how many organizations still lack robust controls, with only fragmented policies and limited incident response. That picture aligns with global findings from McKinsey and others, which note that many companies adopt AI quickly but build risk practices slowly.
There is also the value-delivery challenge. The MIT study on generative AI found that 95% of generative AI business projects are failing to produce meaningful returns, even though many use advanced models. MLOps alone does not guarantee success. Teams still need clear problem selection, strong product management, and realistic expectations.
Finally, legacy infrastructure and compliance constraints slow many MLOps initiatives. Some organizations must support on-premises environments, strict data residency rules, or mainframe integrations. Off-the-shelf cloud MLOps platforms may not fit easily.
Conclusion
MLOps sits at the intersection of data science, software engineering, and operations. It answers a practical version of the question “what is MLOps?” by defining how teams should build, deploy, monitor, and govern ML systems over their entire lifecycle. The discipline has grown rapidly as AI adoption has spread and as companies realized that model performance in a notebook means little without reliable production operations.
At Designveloper, we help companies turn that foundation into real, high-impact systems. Over the past decade, our team has delivered 100+ software and AI-driven projects across the U.S., Europe, Japan, Singapore, and Australia. From healthcare analytics platforms to fintech risk-scoring engines and retail automation solutions, we’ve implemented end-to-end data pipelines, ML model deployment frameworks, and cloud-native infrastructures that directly support MLOps best practices.
With strong engineering standards, Agile delivery, and a team experienced in tools like MLflow, Kubeflow, AWS SageMaker, Docker, and Kubernetes, we help businesses adopt MLOps in a way that is scalable, secure, and aligned with long-term product goals.
Also published on

Share post on










Related Articles

How To Build AI Agents with LangChain: The Complete Guideline
How To Build AI Agents with LangChain: The Complete Guideline Published June 30, 2026
A Practical Guide To AI Agent Architecture With Diagrams
A Practical Guide To AI Agent Architecture With Diagrams Published June 02, 2026
What Is MLOps? Understanding MLOps Lifecycle and How It Works
What Is MLOps? Understanding MLOps Lifecycle and How It Works Published December 10, 2025





















