












RAG vs Fine-tuning: Which Is Better for Improving AI Models?
RAG and fine-tuning are two common techniques to improve the inherent capabilities of large language models (LLMs) like GPT-4 or LLaMA-2. They aim to tailor the LLMs to specific use cases. Also, they help various businesses handle certain problems, like customer service for e-commerce shopping or internal knowledge for legal professionals. So, between RAG vs fine-tuning, which one works better for enhancing AI models? Let’s learn about the different traits of each technique and the best cases to use them.
What is RAG?
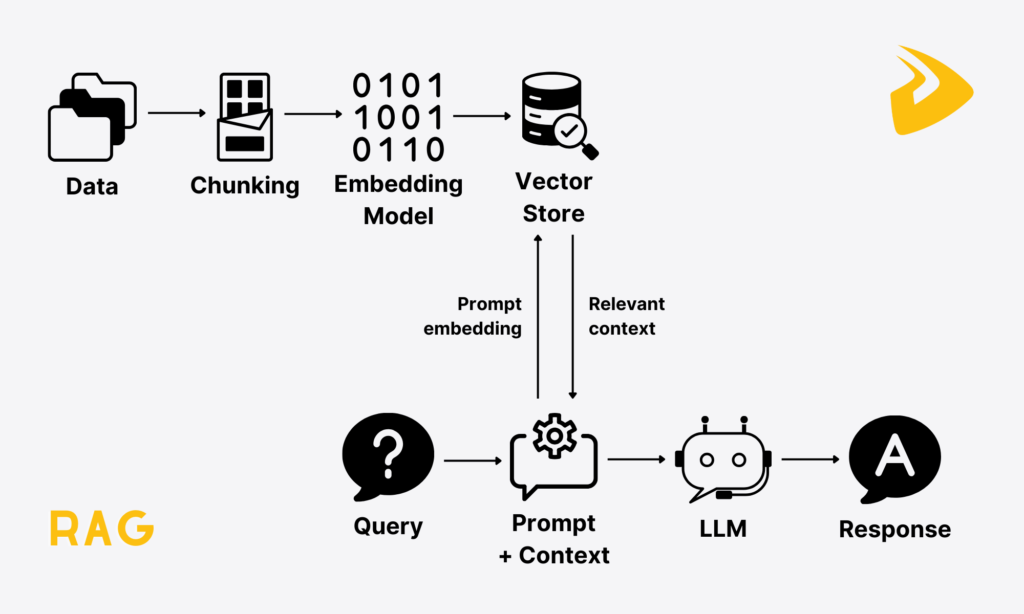
RAG stands for Retrieval-Augmented Generation. This technique focuses on two main processes: retrieval and generation. On the surface, it basically works by retrieving relevant data from external databases based on a user’s query and passing the data to an LLM. This allows the LLM to generate factually grounded and contextually relevant responses.
LLMs rely heavily on their pre–trained data to generate responses. However, this data might be obsolete and too general for a specific task. For example, if you ask, “What is the latest interest rate set by Bank A in 2025?” the model may return an incorrect answer, as its core knowledge base only covers information up to 2023.
Further, even when the LLM’s internal source doesn’t contain information or evidence to resolve a query, it still tries to make up the answer, instead of saying “I don’t know.” This phenomenon is “hallucination.” It’s very risky if the LLM fabricates for some strictly regulated or sensitive cases, like legal advisory or medical diagnosis. That’s why RAG needs to come in and address these limitations of LLMs by equipping them with factual, up-to-date information.
How does RAG work?
Inevitably, the RAG workflow behind the scenes is more complex, involving various systems and tools around the LLM itself. These systems include embedding models, vector databases, and more to ensure the data will flow seamlessly from external sources to the LLM. Accordingly, RAG works in the following two phases:
- The Offline Phase – Data Ingestion and Indexing: This stage prepares data for later retrieval and generation. A RAG pipeline can ingest any type of data, but primarily unstructured text data.
- Various RAG frameworks, like LangChain or Haystack, offer necessary tools (e.g., document loaders, text splitters) to pre-process this data and turn it into a standard format (e.g., LangChain’s
Documentobjects). This data is also chunked into smaller pieces (measured in tokens) with overlap so that the system can absorb the content well. - Then, an embedding model converts these chunks into numerical vectors (“embeddings”) that the LLM can read and interpret. These embeddings are stored in a vector database for later similarity search and retrieval.
- Various RAG frameworks, like LangChain or Haystack, offer necessary tools (e.g., document loaders, text splitters) to pre-process this data and turn it into a standard format (e.g., LangChain’s
- The Online Phase – Retrieval and Generation: Now that you’ve prepared a knowledge base for the LLLM, it’s time for the online part. This stage starts with a user sending a query. Similar to the data, the query is also embedded using the same embedding model. Then, the retrieval system will compare the numerical vectors of both the query and the knowledge base to find the most relevant chunks. Then, these chunks are retrieved and fused in the prompt (a command guiding the LLM to respond), along with the original question. This helps the LLM return a context-aware answer.
Use cases for RAG
LLM apps often integrate RAG when accurate, up-to-date, and relevant information matters. For example, a lawyer asks, “What precedents exist for data breach liability in healthcare?” After receiving the query, the RAG app needs to pull relevant case law summaries from internal legal databases, emphasize the most cited cases, and create a structured legal brief with references. A wrong response in this case leads to wrong decision-making and even legal risks.
With this capability, RAG is adopted widely across domains, including:
- Enterprise knowledge management
- Customer support automation
- Legal and compliance research
- Healthcare and medical assistance
- Financial services and research
- E-commerce and product search
- Education and e-learning
- Research and scientific discovery.
What is Fine-Tuning?
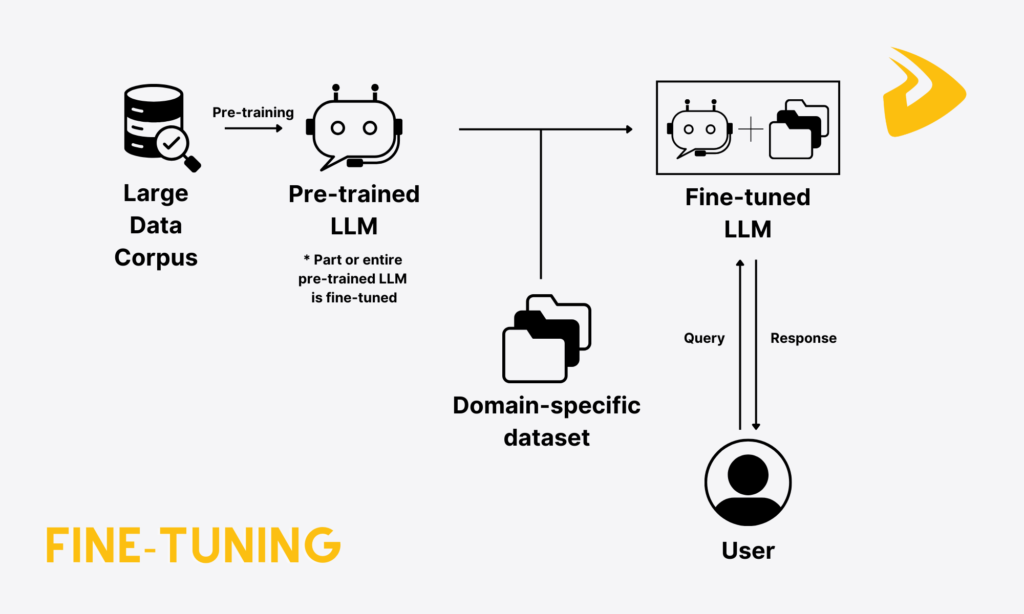
Fine-tuning is the technique of re-training the LLM further on a smaller, domain-specific database to perform specific tasks. This process allows your business to adjust the model’s parameters (weights) to fit the knowledge, style, and tone of a certain use case without the need to build the model from the ground up. For example, you can fine-tune the LLM to your company’s internal source of HR and IT documentation so that it can help employees answer relevant questions, like “What is the company’s maternity leave policy?”.
Imagine fine-tuning as a process of re-training a high school student (who knows a bit of everything) on a specific field (e.g., medical, legal, or finance) when he gets into university. Like RAG, fine-tuning is also adopted to help LLMs overcome their inherent limitations, including hallucinations or inaccuracy.
How does fine-tuning work?
Fine-tuning is considered supervised learning. This means you train the base model (e.g., GPT, Falcon, or LlaMA) on a focused set of external data where the input (prompt) and the expected output (response) are already known. In other words, data used for training includes various labeled examples that are a mix of prompts and expected responses. For instance, you want to fine-tune a model for customer service:
- Input (prompt): “Customer: My order hasn’t arrived yet.”
- Expected Output (label): “Model: I’m sorry for the delay. Can you share your order ID so that I can check the status?”
The model will generate a response during fine-tuning. What if the response differs from the expected output (let’s say, “I’m sorry to hear that. Please wait for a few more days. If your order is still delayed, you can contact us through the hotline: XXXX-XXXX.”)? In this case, the model will correct it by slightly modifying parameters (the guidelines controlling its behavior) until it learns how to generate responses closer to the labeled ones.
Fine-tuning can happen in two different ways:
- Full Fine-Tuning: This refers to updating all parameters of the model. This makes the model more powerful, yet wastes lots of compute, memory, and storage.
- Parameter-Efficient Fine-Tuning (PEFT): This refers to adjusting a small number of parameters. LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA) are two common PEFT techniques.
- The former allows you to add small “adapter layers” and train the model on just those layers, while other parts of the model stay frozen.
- Meanwhile, the latter compresses the model into a smaller, lower-accuracy format. This process is known as “quantization.” Then, it applies LoRA adapters to the format. This approach enables you to fine-tune huge models on regular hardware, such as a single GPU, instead of using various powerful GPUs to handle like full fine-tuning.
Use cases for fine-tuning
Fine-tuning is useful if you want AI models to:
- Handle domain-specific knowledge that rarely evolves. This knowledge may cover specialized jargon, terminology, company voice, etc. For example, a healthcare chatbot is trained on medical guidelines and patient records to create clinically precise answers.
- Speak your company’s unique voice, with corresponding vocabulary, tone, and style.
- Enhance accuracy in niche scenarios where small mistakes matter, like tax or legal services.
- Perform structured prediction tasks, like sentiment analysis, intent detection, or classification. For instance, a fine-tuned model in e-commerce takes over classifying customer reviews (e.g., “shipping issues” or “product quality”) for faster resolutions.
- Support code generation and development.
- Generate creative content for specific genres, tones, or formats.
When Should You Use Retrieval-Augmented Generation (RAG)?

RAG is especially useful if you require up-to-date information and transparent sources for the model’s response, but training data or compute resources are limited.
Rapidly Evolving or Vast Knowledge Domains
As we mentioned, the LLM’s knowledge has a date cutoff, and the model cannot dynamically update new data after training. So, RAG is helpful if your domain changes continuously. This makes RAG different from fine-tuning, which allows you to update the model on hard-to-change information (typically specialized jargon).
For instance, in cybersecurity, new vulnerabilities appear every day. A RAG chatbot can retrieve the latest information from CVE databases to identify and analyze the right risks. In finance, central banks frequently update interest rates and policies. When a user asks about the latest Federal Reserve rate decision, the RAG assistant can pull the latest announcement from the Fed’s website and provide a precise summary, instead of depending only on obsolete training data.
Limited Training Data or Compute Resources
Fine-tuning, as we explained, requires significant labeled datasets. To create such specific training data, your company has to convert raw documents (e.g., PDFs, manuals, or reports) into structured examples so that the model can read and learn from them. However, preparing such documents is labor-intensive, time-consuming, and expensive, as people have to read through the raw documents, generate possible questions, write correct answers, and format everything properly. Not to mention that even PEFT consumes more compute power than RAG.
Therefore, if you have limited resources (compute and training data) to fine-tune the model, RAG is a better option. Accordingly, it allows the model to work with different external databases without retraining.
For instance, small e-commerce companies don’t have enough financial resources to handle fine-tuning for customer support. So they leverage RAG-powered chatbots to search for real-time information directly from FAQs, manuals, or past tickets. Or in healthcare, clinical centers may want AI assistants to answer questions about their specific services, drug interactions, and more. Instead of fine-tuning them on millions of clinical documents and policies, RAG helps produce evidence-backed responses while reducing costs.
Focus on Accuracy and Traceability
In industries such as medical, legal, or finance, information accuracy is paramount. Powered by RAG, AI models can offer factually accurate answers backed by trusted sources. Further, RAG-powered chatbots can attach source links to their answers, allowing users to trace back to the original source for double-checking. Also, RAG is considered to keep your sensitive or confidential data safe in external databases, rather than fusing this data into the model.
Thomson Reuters, a leading business information and content technology company, opted for RAG to empower its LLM solution in customer service. The company specializes in providing products and services to different customers, especially experts in legal and tax who need accurate information to resolve their existing issues. Therefore, RAG is applied to help customer support reps find possible solutions from hundreds of thousands of knowledge base articles for these specialists.
When Should You Use Fine-Tuning?

RAG is good, but not for all situations. Instead, fine-tuning is the right option if you need an LLM system to go beyond general knowledge and adapt deeply to your specific use case. Additionally, fine-tuning allows the model to generate responses that consistently reflect your brand voice and style.
Specialized Use Cases or Unique Data Formats
Fine-tuning is more effective than RAG if your chatbot needs specialized expertise, unique document structures, or a particular communication style. This is because the fine-tuned model can learn how to process your data and generate specific output with consistent formats. Meanwhile, RAG-powered chatbots only focus on the external data fed to them. If such external documents are inconsistent in formats or communication style, it’s hard for the chatbots to speak the same voice as your brand.
For example, a law firm may fine-tune a language model to create contracts with the clauses and formatting in alignment with the company’s own style. Or a healthcare provider fine-tunes an LLM on anonymized clinical notes and lab reports. It then learns how to summarize diagnoses and suggest the next possible steps using the exact medical language doctors prefer.
Enhancing Base Model Capabilities
Base language models excel at reasoning, but they’re not natively optimized for specific skills, like writing code in a proprietary framework or following specific instructions in a law firm. Therefore, fine-tuning comes in to improve the model’s capabilities for particular tasks.
For instance, a fintech company teaches a model about its proprietary API documentation. This allows the bot to generate ready-to-run, accurate code that communicates well with their APIs. Or an education platform may use its fine-tuned model to grade a student’s IELTS writing essay using specific band descriptors published by Cambridge. In this case, the model learns not only to check grammatical structures and word use, but also to match the grading style and rubrics.
Balancing Resources and Deployment Efficiency
RAG is powerful yet comes with longer response times (“higher latency”) and higher system complexity. This is because the RAG workflow covers multiple steps, from getting a user’s query, pulling relevant details, and fusing them back to the LLM’s prompt to creating a response. The extra retrieval step adds latency and complexity.
Meanwhile, a fine-tuned model already has the relevant knowledge incorporated in its parameters. The model can require a huge initial investment before fine-tuning. But upon training, the model can completely integrate domain-specific knowledge into its base and run more efficiently. With this capability, a fine-tuned model proves useful when an internet connection gets lost.
When to Combine RAG and Fine-Tuning (Hybrid Approach)?

In some cases, RAG or fine-tuning alone doesn’t work best. Instead, combining them often produces better results, especially when you want to adopt both RAG’s real-time data retrieval and fine-tuning’s deep domain expertise.
Complementary Strengths
A hybrid approach helps two techniques complement each other’s strengths. Particularly, RAG enables an LLM to catch up with the latest information, while fine-tuning keeps the model fluent and consistent in your domain language, workflows, and tone.
For instance, a medical chatbot uses RAG to extract the latest treatment guidelines or drug approvals from verified databases. At the same time, fine-tuning helps the smart assistant learn about anonymized patient records and understand how doctors phrase diagnoses and recommendations. This ensures it stays updated on evolving medical knowledge and generates doctor-like responses.
Hybrid Use Cases
When your responses must blend both internal expertise and dynamic updates, a combination of both RAG and fine-tuning is more advisable. For example, a law firm fine-tunes its legal research assistant on internal document-drafting style, while using RAG to retrieve the latest, most relevant case law or statutory updates. This hybrid approach allows the assistant to generate stylistically and legally correct memos that match the firm’s voice.
Cost and Complexity Considerations
If you decide to combine both approaches, you need to prepare yourself for taking on the challenges of both systems. Fine-tuning requires data prep, ML expertise, and powerful GPUs. Meanwhile, a retrieval system involves extra databases, embedding models, APIs, etc., adding cost and effort to build and maintain the RAG system. Due to the extra cost and complexity, the hybrid approach is only suitable for very high-stakes requirements (often in domains like healthcare or legal) and businesses with robust infrastructure and adequate talent pools.
Despite complexity, combining the two approaches can bring the best results. A smart strategy is to fine-tune just enough for specialization and let RAG focus on what fine-tuning doesn’t cover (e.g., facts or updates). This balance ensures you won’t throw a fortune on over-training, but still get excellent outcomes.
How to Choose Between RAG and Fine-Tuning

After learning about RAG and fine-tuning, you may ask which approach to choose. To identify the best technique for enhancing an LLM, you should consider the following decision factors and ask corresponding questions clearly:
- Stability in Domain-Specific Knowledge: If your domain knowledge often changes, RAG works best because it can retrieve the latest information without retraining. Some popular use cases of RAG include stock market insights, news summaries, or cybersecurity alerts. Meanwhile, fine-tuning is better if your chatbot has to handle specialized tasks that require stable domain-specific knowledge. Consider fine-tuning for use cases such as legal document classification, medical image analysis, or customer support in a niche domain. Ask:
- Does your data change regularly or remain static?
- Resource Availability: Fine-tuning is a resource-intensive approach. It requires more labeled data, computer power, ML expertise, and even high initial investments. So, if you have limited resources, adopt RAG to start with. Ask:
- Do you have enough clean, labeled data to fine-tune a model?
- What is your budget?
- Accuracy and Freshness: RAG offers up-to-date knowledge. Meanwhile, fine-tuning emphasizes more reliable, skill-based accuracy and gives you more control over model behavior or output style. Ask:
- Do you need real-time, constantly updated knowledge? Are highly specialized skills or task accuracy crucial to your company?
- Do you prioritize output consistency in communication styles, voice, and language?
- Technical Expertise: Fine-tuning requires in-depth technical skills and experience in natural language processing (NLP), deep learning, data reprocessing, model configuration, etc. Meanwhile, RAG requires coding and architectural skills, but with RAG frameworks, building and maintaining such a system is less technical than fine-tuning. Ask:
- What’s your team’s technical expertise?
By weighing these decision factors, you can pick the most suitable option for your business.
Also published on

Share post on










Related Articles

AI Chatbot Development: A Step-By-Step Guide
AI Chatbot Development: A Step-By-Step Guide Published July 15, 2026
Claude Vs ChatGPT Vs Gemini For Coding: Which AI Fits Your Workflow?
Claude Vs ChatGPT Vs Gemini For Coding: Which AI Fits Your Workflow? Published July 06, 2026
12 vLLM Alternatives for Efficient and Scalable LLM Inference
12 vLLM Alternatives for Efficient and Scalable LLM Inference Published July 06, 2026





















