












What Is GraphRAG? Knowledge Graphs for LLMs
You may know that RAG (Retrieval-Augmented Generation) is an advanced technique that improves the inherent capabilities of LLMs in generating responses to a user’s query. In 2024, we continued to see an emerging concept: GraphRAG, which was introduced by Microsoft Research to address the limitations of baseline RAG systems. So, what is GraphRAG exactly, and how does it work? Keep reading and learn about all the essentials of GraphRAG in today’s blog post!
What is GraphRAG?
GraphRAG is an advanced version of standard RAG, or at least, you can say so. It’s a combination of a knowledge graph and RAG. So to understand what GraphRAG is, you have to grasp its two core components:
- RAG is a technique that allows large language models (LLMs) to search and retrieve relevant, up-to-date information from external data sources to generate more context-aware, factual answers. Instead of relying on their internal knowledge base that has a cutoff date, LLMs can “learn” new knowledge externally. This reduces hallucination problems and increases the likelihood of building more relevant responses to a given query.
- A knowledge graph is a tree-like structure that maps entities and their edges. Instead of keeping plain text data or vector stores, the graph turns the raw input into nodes (“entities”) and connects them with edges that represent their explicit relationships.
Combining these two components, GraphRAG uses knowledge graphs to present information visually, letting LLMs trace along its edges to extract more accurate or relevant data. This capability makes GraphRAG useful in handling complex requests that demand multi-hop reasoning.
How does GraphRAG differ from standard RAG?
The main differences between GraphRAG and baseline RAG lie in their type of retrieval and the structure of knowledge. Standard RAG aims to search for the most relevant chunks of text and fuse them into the LLM. Meanwhile, the main purpose of GraphRAG is to look for the most relevant entities and their explicit relationships and feed that structured context to the LLM.
Below is a comparison table of these two RAG approaches across various factors:
| Key Components | GraphRAG | Standard RAG |
| Data Types Handled | Combines unstructured, structured, and semi-structured data in one connected graph | Mainly unstructured text embedded using neural networks |
| Knowledge Store | A knowledge graph of entities (“nodes”) and their explicit relationships (“edges”) | A vector database containing embeddings (numerical values of text chunks) |
| Retrieval | Graph traversal search; follow nodes, edges, and multi-hop paths relevant to a query | Similarity search; find the closest vector embeddings to a query vector on a high-dimensional space |
| Context to LLMs | Subgraph, graph summaries, or text obtained from nodes/edges are sent to LLMs to maintain relationships | Extracted text chunks are combined and fused into the LLM’s prompt, along with the original query |
| Reasoning | Inherently support multi-hop reasoning | Reasoning across various related facts requires extra prompt engineering |
| Explainability | Support provenance and reasoning; allow LLMs to trace answers back to nodes/edges | Hard to understand why certain chunks are extracted or why the model connected facts |
Example: Standard RAG vs GraphRAG
To better understand those differences between standard RAG and GraphRAG, let’s see the example below:
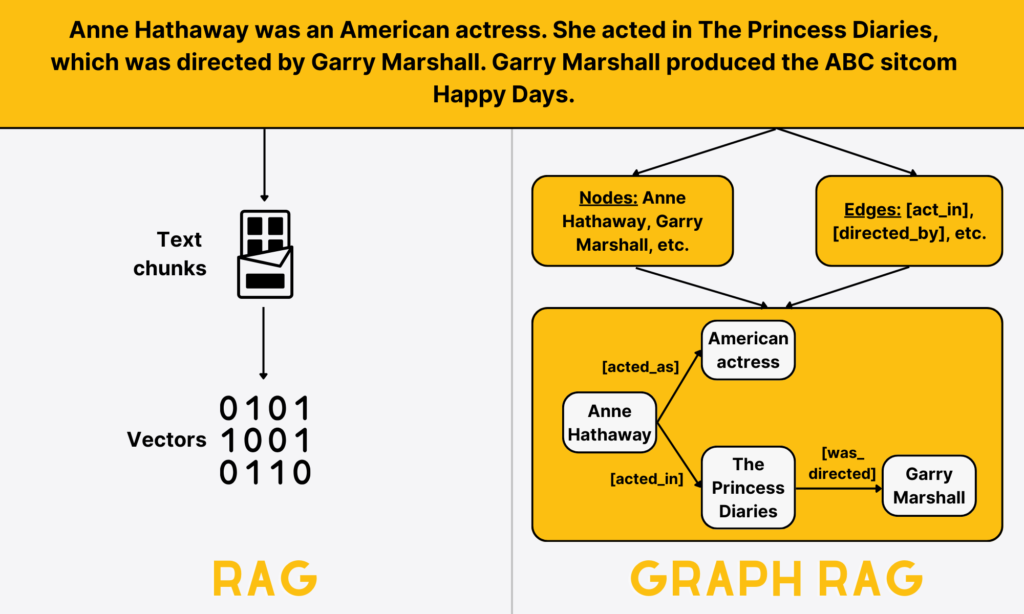
Suppose we have the following sample text:
“Anne Hathaway was an American actress. She acted in The Princess Diaries, which was directed by Garry Marshall. Garry Marshall produced the ABC sitcom Happy Days.”
Standard RAG breaks down text into small pieces (“chunks”), transforms each chunk into a vector embedding, and stores it with the plain raw text.
If you ask, “Who directed the movie starring Anne Hathaway as a princess?”, the baseline RAG system looks for vectors similar to the question and returns D2 and D3 as the most relevant chunks. Receiving these chunks and the question, the LLM generates a suitable answer.
Meanwhile, GraphRAG represents the text as nodes (entities) and edges (relationships).
Nodes: Anne Hathaway, The Princess Diaries, Garry Marshall, Happy Days, ABC
Edges:
Anne Hathaway – [act_in] – The Princess Diaries
The Princess Diaries – [directed_by] – Garry Marshall
Garry Marshall – [produced] – Happy Days
Happy Days – [aired_on] – ABC
If you ask, “Who directed the movie starring Anne Hathaway as a princess?” GraphRAG traverses along the graph-based data: Anne Hathaway → The Princess Diaries → Garry Marshall → Happy Day. It then traces these connected nodes to identify the directed_by relationship between The Princess Diaries and Garry Marshall, offering the evidence-backed subgraph or graph summary to the LLM.
This entire path is visual. So, you can track exactly how the system reasons through the question to locate the most accurate answer for the query.
Key components of GraphRAG
GraphRAG is comprised of various components. They include:
1. Knowledge graph
At the core of GraphRAG is a knowledge graph. This is a network of nodes representing key entities (people, concepts, products, etc.) in a large corpus and edges representing the relationships between these nodes.
Unlike standard RAG, which stores vectorized unstructured text, GraphRAG keeps a wide range of data types from different sources (e.g., structured databases, unstructured text, or semi-structured logs). Besides, a knowledge graph can also store vector embeddings in nodes and edges to support semantic search.
Once the graph is built, it will be indexed to ensure that the system can extract the most relevant nodes and their subgraphs fast, even under growing data volumes.
2. Query processor
When a user sends a query, GraphRAG first preprocesses it to identify key entities and relationships truly relevant to the knowledge graph.
The query processor is an important component of GraphRAG in this step. It uses machine learning techniques like named-entity recognition or relational extraction to recognize names or concepts in the query and map them to corresponding nodes.
If the query is too complex or broad, it will be divided into various sub-queries or multi-hop steps to guide the GraphRAG system to the right parts of the graph structure.
3. Graph-based retriever
The retrieval component of GraphRAG locates and pulls relevant nodes and edges from the knowledge graph based on the processed query.
Instead of just retrieving similar information, it will traverse the graph. In other words, GraphRAG will follow edges to collect connected entities and relationships that form the context for the response.
Some techniques used for graph-based extraction include:
- Graph traversal algorithms, such as breadth-first search (BFS) or depth-first search (DFS), identify the exact nodes and edges that match the given query.
- Graph neural networks (GNNs) learn patterns from the features of nodes/edges and how the entities are linked. They can identify the most relevant parts of the graph, even when the relationships are indirect or complex.
- Adaptive retrieval quickly decides how deep or wide to explore the graph. For instance, it may scan a small neighborhood if a query is simple, while expanding the search for a complex one.
- Embedding models transform nodes, edges, and entire subgraphs into vectors to perform similarity search.
4. Context organizer
GraphRAG includes a context organizer to refine the extracted graph data by eliminating noisy or irrelevant information. This is implemented using techniques like graph pruning, reranking, summarizing, or context grouping.
Further, GraphRAG also converts the organized graph data into a format (e.g., readable text or structured triples) that the LLM can read and understand. This ensures that the graph data is clean, concise, and ready for response generation while preserving the essential meaning and relationships.
5. Generator
Once the graph data is cleaned, GraphRAG will use LLMs or other generation modules to generate context-aware responses using natural language. These final outputs may be text or new graph structures for scientific tasks.
Beyond the answers, the system can explain its reasoning and trace its responses back to corresponding nodes/edges. This makes its output evidence-backed and reduces hallucination problems.
How does GraphRAG work?
So, how can GraphRAG combine the given core components to perform high-quality searches? Let’s explore how it works:
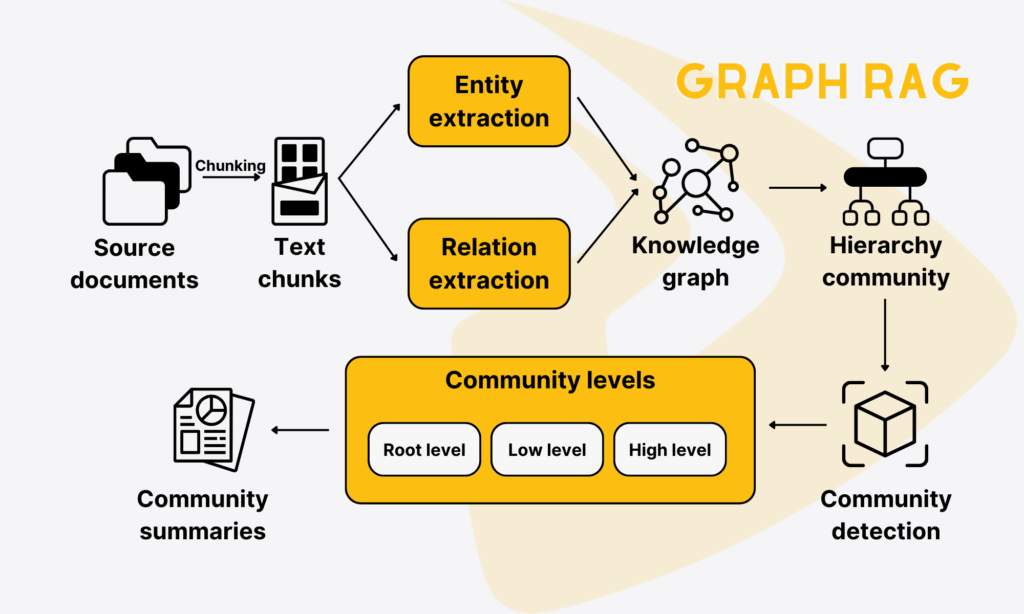
GraphRAG first uses a large language model (LLM) to scan the corpus of all your source documents to identify key entities and their relationships. These entities and relationships become the nodes and edges of a knowledge graph.
As the graph might be huge and complex, GraphRAG manages it by using algorithms to partition the graph and group closely related entities into communities. It then organizes these clusters into a hierarchy that places broader, more general groups higher up and small, tightly related groups at the bottom.
Then, GraphRAG leverages an LLM to briefly describe each group. This process starts with generating short summaries for the smallest communities and then for higher levels by combining or referencing the low-level summaries. Together, GraphRAG creates a multi-level set of summaries that provide local details and global insights over the entire corpus.
When a user sends a query, GraphRAG will use these summaries to provide answers through two steps:
- Map: Each community summary is used independently to offer partial answers to the query.
- Reduce: The GraphRAG system then combines these answers into a final response.
Note that GraphRAG can work with three “out-of-the-box” data formats, including:
- Plain text (like
/txtfiles) for unstructured text - CSV files
- JSON files for structured objects.
Regardless of the original formats, GraphRAG converts them into a DataFrame documents with a unified schema. Some key schemas include id, text, title, creation_date, and metadata.
Why GraphRAG Matters For Large And Complex Datasets?

A knowledge graph plays an increasingly important role in LLM applications, especially when these apps have to handle large, complex data volumes. One research has shown that its global value will likely reach more than $6.9 billion in 2030, highlighting its significance in this AI era.
So why does GraphRAG become a crucial, effective method for large-scale datasets?
To answer this question, we have to look back at existing challenges related to such datasets. Various organizations now collect data from various scattered sources, like enterprise logs, customer records, research papers, and more. They contain millions or even billions of data points, mixing structured tables, semi-structured formats, unstructured text, and multimodal information.
However, relationships between entities in such data are ambiguous or spread across numerous files and formats. This makes it challenging to identify their exact connections. Not to mention that tracking the original source of facts is hard when data is scattered.
Further, the amount of data might be too big for a single LLM to handle due to its limited context window. This results in the loss of important context.
But standard RAG fails to address these problems for several reasons.
- First, it doesn’t inherently have explainability, so you may not be sure whether the information it fetches is truly relevant to your queries and how it reasons through complex queries to return answers.
- Second, standard RAG still struggles to connect or compare disparate pieces of information meaningfully.
- Third, it faces difficulties in interpreting semantic summaries within large and complex information sets.
How GraphRAG addresses these issues
GraphRAG adds a knowledge graph and hierarchical summaries to traditional RAG. This extension solves the limitations above directly:
- Relationship-aware retrieval: The GraphRAG system uses graph traversal and multi-hop reasoning to locate the most relevant nodes and follow edges to neighboring nodes. This helps it form the most suitable context for answers.
- Effective organization of large, complex data: The graph is broken down into communities and summarized bottom-up. This hierarchy allows GraphRAG to find only the most relevant subgraphs, reduce noise, and keep processing scalable.
- Provenance and explainability: The graph structure of GraphRAG lets you trace answers back to the source references of retrieved nodes. This helps check whether the answers are reliable and truly relevant.
- Flexible data processing: GraphRAG contains not only unstructured text but also structured tables and semi-structured logs. This makes it ideal to handle mixed sources of data.
Large and complex datasets require more than a simple vector search to handle. GraphRAG fills the gap of traditional RAG by organizing data in a graph structure and using LLMs to unlock hidden relationships, provide clear reasoning paths, and scale to vast data volumes.
Step-by-Step Guide for Executing GraphRAG

So, how can you implement GraphRAG for your AI application? This section will guide you through the five key steps to execute this technique effectively.
Step 1: Prepare Your Dataset
First, you need to prepare datasets to structure your raw data so that GraphRAG can read it well in both the graph construction phase and retrieval/generation processes. Here’s what you need to do in this step:
- Collect data: Gather all the sources (e.g., documents, transcripts, domain knowledge, etc.) you want to include. Then, decide which parts of these data sources are necessary for your downstream tasks (e.g., FAQs).
- Preprocess data: Clean and normalize the data by removing duplicates, HTML tags, and special characters, as well as normalize spelling, split sentences, and possibly apply NLP preprocessing methods (e.g., lemmatization).
- Chunk data: Break the data down into chunks and add metadata (e.g., document ID, date, section, source) if any.
- Extract entities and relationships in the data: Use named-entity recognition (NER) models or OpenIE to identify entities inside chunks. Then, leverage relation extraction tools to propose their relations. Optionally, you can link the retrieval entities to their references (e.g., knowledge base IDs or internal ontology) to keep these entities consistent.
- Filter: Identify high-confidence triples based on model scores or confidence thresholds. Note: A triple is a single fact presented in the form (head entity, relation, tail entity). Example: Anne Hathaway – [act_in] – The Princess Diaries.
- Embed (optionally): You can embed text chunks or subgraphs using embedding models and store them in vector databases to perform similarity retrieval alongside graph-based searches.
Step 2: Build the Knowledge Graph
Once your datasets are ready, let’s build a knowledge graph by turning the retrieved entities, nodes, or triples into a structured graph. Below are some tasks you need to do to build such a graph:
- Design schema: Define entity types (e.g., Person), relation types (e.g., “works_for”), and constraints (e.g., allowed relation domains).
- Populate graph: Insert entities as nodes (with their attributes or metadata) and the filtered triples as their edges. For each node/edge, record provenance (e.g., chunk id, confidence, or timestamp).
- Summarize: Apply graph algorithms (e.g., Louvain, Leiden, or clustering) to group related nodes/edges in the knowledge graph. Also, create a summary (by using an LLM) for each community.
- Index the graph: Store the graph in backend systems (e.g., Neo4j, Dgraph, TigerGraph, or custom in-memory databases). Further, add indexes on key node properties (e.g., IDs, names) to search nodes/edges quickly without scanning the entire graph. Optionally, you can generate graph embeddings for a node’s neighborhood or small subgraphs to enable hybrid search.
Step 3: Connect to Your LLM
Your GraphRAG system requires an LLM to implement effective retrieval and generation. Follow these subtasks to set up the infrastructure to query the model:
- Choose and deploy the LLM: Select a suitable large language model for your project, whether OpenAI’s GPT series, fine-tuned models, or open-source models (e.g., Claude, Llama).
- Design prompt templates: Craft prompt templates that combine extracted information with user queries. These templates are crucial in telling the LLM how to generate responses.
- Build query processor, retriever, and organizer modules: Build or add the query process to transform incoming queries into graph-search instructions and well-structured LLM prompts. Besides, you need to build the retriever to pull relevant nodes, triples, or subgraphs from the knowledge graph, and the organizer to reorder the search results before passing them to LLM prompts.
- Connect all modules into a GraphRAG pipeline: Orchestrate all the modules to create seamless graph retrieval and search.
Step 4: Run Retrieval + Generation
Now, you already have a complete GraphRAG system. Let’s run the retrieval and generation processes based on incoming queries.
When a user delivers a question, GraphRAG will translate the query into graph-level instructions and use pruning/extraction strategies to pull relevant subgraphs. The system then turns the retrieved subgraphs into textual formats that the LLM can understand.
Similar to traditional RAG, GraphRAG will fuse the context and query into the prompt so that the LLM can return context-aware, accurate outputs.
Step 5: Test, Evaluate & Optimize
Last but not least, test and evaluate your GraphRAG system’s performance to ensure it runs as intended. To measure its performance and spot weaknesses for fine-tuning the system, below is what you need to do:
- Use evaluation metrics and benchmarks: Identify essential metrics and benchmarks to evaluate your system’s retrieval, generation quality, latency, cost, and even domain-specific task completion. Some common metrics include precision, recall, BLEU, or hallucination rate.
- Test on held-out query sets: Create your own test questions or use a benchmark dataset (e.g., Hotpot QA or domain-specific QA) to assess those queries. Don’t forget to log failed cases like wrong answers, missing relations, or hallucinated facts to analyze the weaknesses of the system.
- Analyze errors to evaluate the system’s quality: Wrong answers may come from many different reasons. So, check the following factors:
- whether the extracted subgraph missed important edges or nodes
- whether entity or relation extraction errors resulted in missing or incorrect graph edges
- if the LLM misunderstood the graph context or relation semantics.
After evaluating GraphRAG’s performance, you can apply optimization strategies to improve it. Some common strategies include graph pruning, reranking, prompt tuning, query rewriting, or subgraph size adjustments.
Re-run the evaluation after each change and monitor GraphRAG’s performance continuously. This iterative improvement will help you optimize the system to ensure it operates in the way you want.
Several Varieties of GraphRAG

GraphRAG comes in different varieties. Each defines what kinds of information the graph contains and how the LLM uses it to generate a response. Understanding each variety’s characteristics and when to use them will help you pick the best fit for your AI application.
Graph as a Content Store
This GraphRAG variety stores semantic metadata about documents (like keywords, topics, or authors, or timestamps) instead of raw facts. It works by pulling the most relevant document chunks and delivering them to the LLM for answering a question.
This GraphRAG variety proves useful when your data is mostly text plus metadata and you already have a vector database for embeddings. When user queries need relevant textual information rather than exact facts, this GraphRAG variety is the fastest way to extract data.
Example use cases:
- An enterprise content hub directs users to the right policy document.
- A research portal answers the question, “Find articles about quantum computing written after 2023.”
Graph as а Subject Matter Expert
This GraphRAG variety captures concepts and their relationships (ontologies, taxonomies, and definitions). It offers rich semantic context, including domain knowledge and metadata, but not factual data.
The system, in this case, identifies the main concepts in the user’s natural language query, retrieves their definitions and relationships from the graph, and fuses them to the LLM.
This GraphRAG variety works best when you want the LLM to reason over concepts or domain knowledge and generate expert-level answers (without raw facts required).
Example use cases:
- A smart medical assistant answers the query, “Explain how type-2 diabetes relates to insulin resistance.”
- A manufacturing support bot responds to the request, “Describe dependencies between production phases in our factory.”
Graph as a Database
This GraphRAG variety stores factual data, domain knowledge, and metadata. The system works by transforming part of a natural language query into a graph query, extracting accurate facts, and letting the LLM summarize them.
This GraphRAG variety is ideal if you prioritize accurate data or calculations.
Example use cases:
- A financial analysis tool answers the query, “List all trades over $5 million made by Company A last quarter.”
- A supply chain agent helps “Search for the most optimal shipping route between Warehouse A and Store B.”
What are the limitations of GraphRAG?
GraphRAG is introduced to enhance traditional RAG and address its limitations. But the technique itself hasn’t been perfected and still presents several challenges.
It struggles to support scalability. When data volumes or traffic grow, GraphRAG at its core must handle both a growing knowledge graph and the heavier computing demands of an LLM.
GraphRAG requires a lot of computing power. Even Microsoft confirmed that fact. This way, when knowledge graphs become larger and more complex, tasks such as multi-hop reasoning, subgraph sampling, and re-ranking become costly. Not to mention that adding GPUs, sharding, or model compression can increase system complexity.
GraphRAG is a complex pipeline that covers different components, like a graph database, a query processor, and a retriever. Mismatched data formats or high latency between the components can slow down or delay the entire system.
Further, if development teams don’t get used to working with such a complex system, they may struggle with GraphRAG’s complex design, component orchestration, and versioning.
Building knowledge graphs is a daunting task. The idea of constructing a network of nodes and edges is great. But for complex, scattered datasets, identifying the right entities and their relationships is hard because their connections are sometimes unclear.
Even with the help of LLMs and advanced techniques for entity and relationship extraction, there’s nothing to ensure the identified nodes and edges are 100% correct. An inaccurate entity or a missed edge can lead to bad final responses.
When and Where to Use GraphRAG

Given the limitations, GraphRAG is still effective in several situations. Understanding where it can work best helps you harness its best value for your business:
Key scenarios
- Data is rich in complex relationships
- GraphRAG works best when entities have deep connections. The nature of GraphRAG is to present the relationships between key entities to help the LLM trace the right data effectively. The more deeply interconnected these entities are, the better the LLM can locate the most relevant info.
- Queries require multi-hop reasoning
- Some queries require more than a single search. For instance, “Which vendors indirectly depend on a factory affected by a recall?” needs the LLM to traverse numerous hops (vendor → product → factory → recall).
- GraphRAG naturally supports handling such multi-step queries effectively and allows the LLM to trace back to the source references of the retrieved information.
- Contextual understanding is critical
- Do you prioritize accurate context, as it significantly affects the quality of responses (e.g., understanding a patient’s entire medical history to suggest the right treatment)? If so, GraphRAG is a good choice because it keeps the LLM’s answers factually grounded.
- The dataset is constantly evolving
- Graph structures are flexible. They allow you to add new nodes or relationships without redesigning schemas. This capability makes it ideal for use cases with ever-changing data, like streaming financial transactions or e-commerce inventories.
Use cases addressed by GraphRAG
GraphRAG comes with built-in graph structures and multi-hop reasoning to resolve the following challenges:
- Inaccurate Retrieval: Standard vector search may miss subtle relationships or over-emphasize keyword similarity. GraphRAG improves retrieval accuracy by using explicit connections between key nodes and multi-hop traversal before sending the context to the LLM.
- Limited Context Understanding: Pure text extraction might return separate chunks without linking them. GraphRAG offers a structured neighborhood of facts, allowing the LLM to reason with a richer context.
- Factuality and Hallucination: Even with strong RAG pipelines, LLMs can hallucinate answers because evidence isn’t clear. GraphRAG mitigates this problem and improves factual accuracy by grounding answers with verified subgraphs and even their source references.
- Efficiency: Graph queries can narrow the data delivered to LLMs, reducing token usage and latency. This is crucial when handling large or constantly changing datasets.
GraphRAG applications
Below are several real-world applications where GraphRAG proves extremely useful:
- Healthcare and life sciences: GraphRAG helps search for patient histories, clinical trial data, and research literature. Further, it can analyze complex medical and biological data to support clinical decisions, drug discovery, and medical research.
- Financial services: GraphRAG can map relationships between entities to identify fraud, track regulatory compliance, or conduct complex risk analysis across financial instruments.
- E-commerce and marketing: GraphRAG can analyze customer behavior, reviews, and products to provide personalized recommendations, enable dynamic pricing, and conduct targeted campaigns.
GraphRAG Tools and Frameworks
To set up and deploy a GraphRAG system, understanding which core components it has and how they work together is not enough. You also need to combine various tools and frameworks for knowledge graph construction, document processing, semantic search, and LLM integration.
Some notable tools for this GraphRAG pipeline include LangChain, LlamaIndex, Neo4j, and OpenAI’s GPT models (or similar LLMs).
- Such AI frameworks as LangChain and LlamaIndex index and retrieve entities and their relationships to help build a knowledge graph. They also host machine learning models to embed the raw data and connect with LLMs to create a seamless GraphRAG pipeline.
- Graph databases like Neo4j store and manage the nodes, edges, and properties of the graph structure. They support graph traversal and semantic relationships to pull out the right subgraphs.
- Large language models, typically OpenAI GPT, can be accessed through APIs. After receiving the graph-derived context, they generate the final responses using natural language.
All these tools and frameworks help you build effective components of a GraphRAG system.
Key Factors for GraphRAG Adoption
Adopting GraphRAG successfully relies on various factors: data quality, computing power, skilled people, and a clear cost-benefit case.
- Data Availability: GraphRAG requires a lot of well-processed, reliable data. Low-quality or inconsistent data can result in wrong or missing graph connections, which hurts retrieval and generation. So, if you don’t have enough data for specific use cases, you can’t develop an effective knowledge graph.
- Data Structure: GraphRAG works best in domains rich in structured or semi-structured data, like healthcare, finance, or supply chain. These sectors inherently keep data as entities and relationships, making it easier for GraphRAG to capture complex relationships.
- Knowledge Graph Construction: When adopting GraphRAG, you must ensure the efficient extraction of entities and relationships. If your team can’t construct or maintain this graph accurately, the entire system will become unreliable.
- Use Case Alignment: GraphRAG delivers the most value when queries require complex reasoning or deep semantic understanding. So, consider whether your specific use cases align with the natural strengths of GraphRAG.
Conclusion
Graph RAG is a powerful approach that combines knowledge graphs and LLMs to retrieve more context-aware, evidence-backed information. Its capabilities help reduce hallucination problems that still exist in naive RAG.
Looking to build an LLM-powered application and want reliable, seasoned professionals on your team? Designveloper is a smart choice. Our team brings deep technical expertise across 50+ modern technologies, with proven experience delivering custom, scalable solutions in sectors like finance, education, and healthcare.
We don’t just stick to what’s tried-and-true. But we actively integrate cutting-edge technologies such as LangChain, Rasa, AutoGen, and CrewAI into our projects. This commitment to innovation means our clients stay ahead of the curve, not just keep pace.
Further, our Agile approach ensures projects are delivered efficiently, on schedule, and within budget. If you’re ready to take your idea further, reach out to us. With our extensive expertise and long-standing commitment to quality, we’re equipped to turn your vision into a fully realized solution. Contact us to discuss your idea further and realize your AI dream!
Also published on

Share post on










Related Articles

Claude Vs ChatGPT Vs Gemini For Coding: Which AI Fits Your Workflow?
Claude Vs ChatGPT Vs Gemini For Coding: Which AI Fits Your Workflow? Published July 06, 2026
12 vLLM Alternatives for Efficient and Scalable LLM Inference
12 vLLM Alternatives for Efficient and Scalable LLM Inference Published July 06, 2026
Cross-Platform App Development: Build Apps For Multiple Platforms
Cross-Platform App Development: Build Apps For Multiple Platforms Published July 01, 2026





















