













Graph RAG vs Traditional RAG: Choosing the Right RAG Architecture
September 30, 2025

RAG (Retrieval-Augmented Generation) is an effective way to extract up-to-date information from external data sources. Over time, we’ve witnessed the evolution of RAG, from traditional RAG to Graph RAG, to improve the data retrieval pipeline. So, what are the main differences between these two techniques? This blog post will clarify several different components between Graph RAG vs traditional RAG, hence helping you pick the right architecture.

Overview of Traditional RAG
Traditional RAG is an approach in which LLMs are fed with up-to-date, relevant information from external data sources to improve their capabilities of generating context-aware, grounded responses.
Unlike human beings, LLMs can’t dynamically access and update new information to answer a question. Normally, they rely heavily on their internal parameters and pretraining corpus that may contain obsolete or incorrect data. When encountering problems they don’t know or aren’t sure about, the models often tend to fabricate answers.
To mitigate their hallucination problem, traditional RAG was introduced to incorporate up-to-date, relevant knowledge into the LLMs. It lays the foundation for various RAG systems, like Graph RAG, and primarily works in text-heavy domains.
How traditional RAG works
So, how does the traditional RAG pipeline work? Let’s take a look:
- The pipeline first ingests and processes text documents from multiple sources (e.g., web pages, customer service guides, or research reports).
- It indexes documents for effective data extraction.
- When a user sends a query, the system uses keyword search or basic query techniques to find relevant information in the indexed documents.
- The extracted information is then fed into the prompt so that the LLM can generate a more accurate, relevant response.
Pros
This approach is considered simple to implement and adopt. It uses existing document management systems and works well with traditional data extraction methods. Further, it works best in sectors with text-heavy documentation, like finance or insurance.
Cons
However, traditional RAG is not without limitations.
- It mainly handles unstructured text data, but this can translate to missing important insights from other data formats.
- When the document library expands, but you don’t have more efficient search methods to process it, the retrieval step may slow down or become less accurate.
- When a response needs reasoning across numerous documents or multi-hop inference, traditional RAG struggles to link or integrate relevant text chunks.
- Traditional RAG struggles to fetch relevant or correct information if queries are too complex or ambiguous.
FURTHER READING: |
1. Is Vibe Coding a Bad Idea or a Problem Misunderstood? |
2. Is Vibe Coding The Future Of Software Development or Just a Trend? |
3. Claude vs ChatGPT vs Gemini: Who Wins in AI Coding? |
Overview of Graph RAG
Graph RAG addresses the inherent limitations of traditional RAG and augments its capabilities of extracting relevant information. It uses graph-structured knowledge to enhance retrieval, context organization, and reasoning across scattered documents.
This approach doesn’t retrieve text chunks independently, but subgraphs or connected knowledge fragments to harness relationships deeply for improved generation.
How Graph RAG works
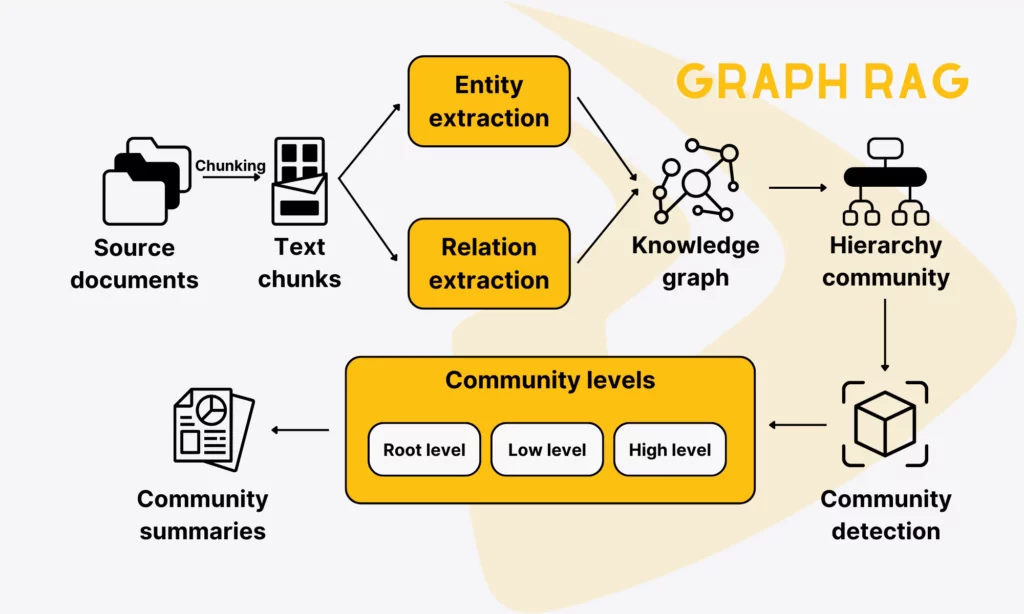
Graph RAG combines LLMs with knowledge graphs that include nodes as the key entities and edges as their relationships. These graph-based data structures allow the models to locate all the relevant information by following edges.
A Graph RAG system often involves various components to perform graph-based retrieval and generation. These components range from query processing and graph retrieval to graph organization and generation.
- Graph-based Query Processing: The system analyzes the user query to identify entities, relationships, and intents. The query can be fine-tuned or expanded to match graph schemas.
- Subgraph Extraction: The system searches for relevant nodes and edges to form a subgraph rather than extracting individual documents. Some techniques adopted in this step include multi-hop traversal, graph-specific ranking, noise filtering, and defining the subgraph’s structural constraints. Graph RAG also employs the hybrid retrieval that combines graphs and text to enrich the context.
- Graph Organization: The system will prune, filter, or organize the raw subgraph to mitigate noise and irrelevant information.
- Graph-to-Text Encoding: The system transforms the reorganized subgraph into the right textual or structured format for the LLM to ingest and understand.
- Generation: Using the subgraph for the context, the LLM will generate suitable responses. Sometimes, the model is prompted to reason over nodes/edges or meet relational constraints to answer the question in a user’s preferred way.
Pros
Various sectors have inherent connections among knowledge elements (e.g., entities, events, citations). Graph RAG is naturally built to model those relationships. By following paths that represent logical or domain relationships, the system can support multi-hop reasoning better, connect multiple isolated chunks, and offer a richer context to responses.
With the extracted subgraphs, the system can explain how it creates answers more clearly.
Further, Graph RAG stores and connects different types of information at the same time.
Suppose you build a scientific knowledge graph. This graph’s nodes can be authors, papers, image datasets, or institutions. While it holds different relationships, like “works_for” or “cited_by.” The mixture of varied data types and relationships helps Graph RAG provide a richer, more complete context.
Cons
Graph RAG itself still presents several challenges.
First, the system doesn’t always retrieve the right subgraphs for the LLM’s prompts. If large graphs contain many irrelevant nodes/edges, the model may produce wrong or misleading answers. So, graph pruning and filtering are significantly important to remove noise and irrelevant information.
Second, Graph RAG consumes a lot of compute power. Tasks, like graph traversal and subgraph extraction, can be computationally expensive at scale.
Third, as Graph RAG covers various core components, designing the right graph structure with traversal policies and integration strategies demands significant engineering and technical knowledge.
A Side-by-Side Comparison of Traditional RAG vs Graph RAG
Now that you’ve understood what traditional RAG and Graph RAG are, let’s learn about their key differences. In this section, we’ll compare these two RAG frameworks in various aspects:
| Key Components | Traditional RAG | Graph RAG |
| Suitable Data Types | Primarily unstructured text; also supports semi-structured text | Supports different data modalities |
| Ease of Deployment | Easier to set up | More complex setup |
| Complex Query Handling | Simple, direct queries | Complex queries requiring multi-hop reasoning |
| Explainable Reasoning | Less explainability | More explainability |
| Speed | Faster for simple queries and well-indexed datasets | Slower due to various tasks (e.g., graph traversal or subgraph extraction) involved |
| Scalability | Scale well to moderate text-heavy corpora; but struggle to work with fast-growing or very large corpora (up to billions of documents) and multiple concurrent queries. | Struggle to scale. |
| Popular Tools | Come with RAG toolkits for document storage, vector embedding, and response generation, like Pinecone, LangChain, or ElasticSearch | Use common tools (like LangChain, LlamaIndex, or OpenAI’s GPT models) and graph databases (Neo4j, etc.) |
Suitable Data Types
Traditional RAG primarily processes unstructured text (e.g., PDF documents, web pages, financial reports, or customer service guides). This capability makes it ideal for real-world applications where queries require textual information as the key relevant data.
Traditional RAG can also index and query semi-structured text (e.g., metadata tags or titles) to improve keyword search or filtering.
However, it still treats each text document independently rather than building a network of entities and relationships. Further, the system also doesn’t work well with non-text data unless you transform it into text.
Graph RAG supports a wide range of data types, including structured tables, semi-structured logs, unstructured text, and even vector embeddings.
If your datasets inherently have relationships (e.g., knowledge bases, graphs, or tables) and queries prioritize harnessing relations between data points, Graph RAG is a good choice.
Ease of Deployment
Setting up a traditional RAG system is generally easy. If your text documents already exist, you don’t need to design a complex data model or create a new database. Accordingly, you mainly need to index documents, build a search or retrieval system (including keywords and possibly embeddings), and fuse the extracted text chunks with the given query to LLMs.
Besides, the deployment of the traditional RAG pipeline is straightforward because it doesn’t need domain-specific schemas or ontologies. Instead of mapping all the entity types and their relationships, you only need to keep and find the text as-is, without the need to clarify how text chunks relate to each other.
Meanwhile, Graph RAG requires more complex setups. You need to retrieve entities and relationships using LLMs and advanced techniques for entity extraction and relation identification.
Further, to set up a Graph RAG system, you need to build a suitable graph schema or ontology and design mechanisms for graph updates and maintenance.
You even need tools and expertise for graph databases and frameworks. If you don’t leverage a managed platform, you need to build more infrastructure for Graph RAG from scratch.
Complex Query Handling
A traditional RAG system works fine if queries are simple and answers live in a single document or a single text chunk. These cases allow the system to perform direct fact lookups and pass the retrieved text to the LLM effectively.
Think of the questions like “What is the interest rate proposed last year in this document?” or “Within how many days can I return a product, according to this policy?”.
However, traditional RAG is incapable of processing queries that require multiple scattered documents or multi-hop reasoning. Therefore, the system might miss important context or insights when working with complex, multi-step queries.
By contrast, Graph RAG is natively built for such complex situations.
As the knowledge is organized in a network of entities and relationships, the system can traverse along paths to reason over relationships, connect related concepts, and handle structured queries. As a result, Graph RAG can generate more complete and relevant responses.
This capability makes it suitable for questions that involve layered reasoning and deep entity connections, instead of only performing one-off fact extraction.
Explainable Reasoning
Traditional RAG lacks the ability to explain why the system extracted specific text chunks and how these chunks relate to one another. In other words, the system only shows you the retrieved text and the final answer, but doesn’t come with visible reasoning paths.
Meanwhile, Graph RAG supports more explainable reasoning. As it uses a knowledge graph to store data as nodes and edges, it can reveal the traversed subgraph based on a user query. The system and users can trace back to the subgraph’s source references by following the path and checking the reliability of the extracted information.
Speed
Traditional RAG is designed to perform faster on simple queries, as it mainly depends on a document index for keyword search. When a user submits a query, the system only needs to search through the index, extract the top-matching text snippets, and deliver the results to the LLM. These simple steps make retrieval more computationally efficient and faster.
Further, if your data is moderate and well-indexed, the traditional RAG system can return results within milliseconds. Quick search and retrieval make it suitable for typical use cases like customer support FAQs, legal documents, or internal manuals.
However, if the document library expands exponentially and users send more complex queries, traditional RAG might require more time and resources to handle. This increases latency and lowers retrieval speed.
Graph RAG works more slowly in various cases. This is mainly because it involves multiple tasks, including graph traversal, subgraph retrieval, entity disambiguation, and relation path finding. Running such graph operations trades off speed for richer, more relevant answers.
Besides, many Graph RAG setups use the hybrid retrieval that first performs standard text search and then implements graph extraction. This two-step process adds extra overhead and complexity to the system.
Scalability
Traditional RAG scales well to moderate text-heavy corpora. If you have thousands or even a few million records, you can add more servers or shard the index to support keyword or even vector search.
However, the system struggles to work with fast-growing or very large corpora (up to billions of documents), multiple concurrent queries, or queries that require combining many extracted text chunks. Besides, when a corpus grows, more irrelevant or near-duplicate information can confuse the retriever. Not to mention that you need more advanced algorithms for reindexing, deduplication, and ranking to maintain high accuracy.
Graph RAG, on the other hand, even confronts more challenges for scalability. When data increases, the graph size will expand accordingly because you have to continuously add new nodes and edges to keep the graph fresh.
Popular Tools
Traditional RAG comes with various open-source RAG toolkits for document storage, vector embedding, and response generation. Some popular tools include Pinecone, LangChain, ElasticSearch integrated with large language models, and more.
Meanwhile, Graph RAG uses specialized tools to build and run a graph-based data pipeline. Some common tools for the GraphRAG pipeline include LangChain, LlamaIndex, Neo4j, and OpenAI’s GPT models (or similar LLMs). Besides, you can leverage pre-built knowledge graph products like WRITER Knowledge Graph to offer graph-based retrieval and explainability.
Evolution of RAG Best Practices
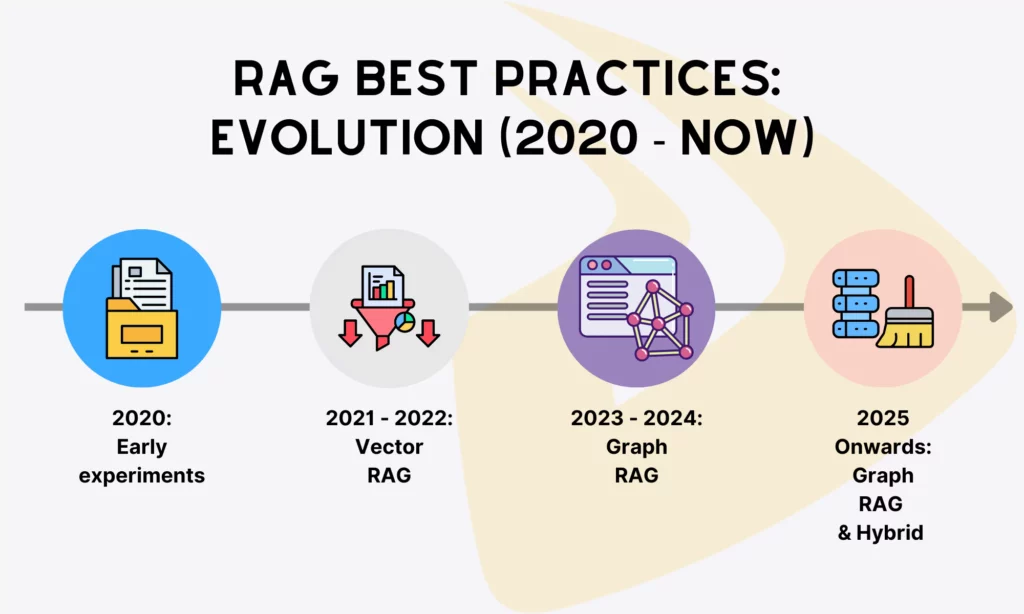
Despite its young age, RAG has quickly grown and become an important technique in LLM applications across domains. Alongside the technique is the evolution of its recommended practices, from vector-only to graph-augmented approaches. Let’s take a quick look at the chronicle of these RAG best practices:
2020: Early RAG experiments
The term RAG (Retrieval-Augmented Generation) was coined and introduced for the first time in the 2020 Meta Research paper.
At that time, the early RAG system focused on combining dense passage retrieval (DPR) with a sequence-to-sequence language model (BERT) to feed external knowledge into generation.
Best practices mostly revolved around careful data preprocessing (like removing stop words or adjusting chunk size) and prompt engineering. They aimed to make the extracted chunks short and relevant.
2021 – 2022: Vector RAG as standard
Vector RAG took the throne in this period, leading to the growing popularity of vector databases and similarity search. Vector databases (Pinecone, Milvus, Weaviate, etc.) and open-source frameworks (LangChain, etc.) gained traction due to its support in end-to-end RAG pipelines.
Various vector databases support not only storing and searching vector embeddings but also applying metadata filtering to narrow the search scope. This enables hybrid retrieval that combines keywords and vectors for higher recall.
Meanwhile, reranking models and cross-encoders played a crucial role in the pipeline to keep search results more precise and relevant to a given query. LLMs integrated in the vector RAG system also had the ability to self-evaluate their generated responses to detect and mitigate hallucinations.
2023 – 2024: Graph-based RAG as the mainstream
Vector RAG was widely applied across knowledge-intensive domains. But when the demands for deeper reasoning and combining diverse data types grew, vector RAG struggled to meet the expectations.
One visible downside with vector RAG was that it could show us the input (“retrieved chunks”) and output (“final answers”), but we didn’t know how it extracted specific chunks and whether the chunks were truly relevant. Especially when handling complex, multi-step, or ambiguous queries, this weakness became clearer.
That’s why Microsoft pioneered in resolving this problem with its Graph RAG concept. This approach blends graph databases (e.g., Neo4j, TigerGraph, Amazon Neptune), LLMs, and advanced algorithms for entity retrieval and relationship identification.
Its main goal is to provide a richer, more complete context to the LLM and maintain provenance for its retrieved passages. This helps reduce hallucinations and improve the LLM’s response quality.
2025 onwards: GraphRAG on the way & Hybrid RAG as the emerging trend
Coming to 2025, we still see the popularity of graph-based RAG and much effort from researchers to improve this approach.
Such frameworks and tools as GFM-RAG, KET-RAG, and NodeRAG are been researched to enhance the capabilities of Graph RAG. For example, GFM-RAG acts as a graph foundation model that can reason over graph structures to capture complex query-knowledge relationships. While KET-RAG enables more cost-efficient indexing.
But beyond Graph RAG, many companies are adopting hybrid approaches to get the best retrieval results. One research has shown that in comparison with traditional RAG, GraphRAG improves context relevance by 11%, while hybrid GraphRAG boosts factual correctness by 8%.
Besides, RAG as a Service is also on the rise, with an estimated global value of $56.5 million in 2025. This is an inevitable result of the growing demands for real-time data processing and improved accuracy, especially in domains like finance, healthcare, and telecommunications.
When Should You Use Graph RAG vs Traditional RAG?
Given their own strengths and weaknesses, when should you leverage traditional RAG and Graph RAG? Let’s explore the specific use cases for each:
When should you choose Graph RAG?
Graph RAG works best for the following use cases:
- Your application requires multi-hop reasoning. If responses require a chain of facts (like A affects B, which impacts C), a knowledge graph is needed to explicitly traverse the connections to return logical answers with connected facts.
- Your data is rich in entities and relationships. In situations where entities (people, products, events, etc.) are deeply interconnected, Graph RAG is the best choice. Some common examples include fraud detection, biomedical research, supply chain networks, and social graphs.
- Explainability matters. Knowledge graphs extract subgraphs and even source documents to generate a response. They allow users to trace back the original sources to check the answer’s reliability and enable regulatory compliance.
- You want to integrate different data types. Graph RAG keeps various data types, from structured tables and event logs to unstructured text and metadata.
In short, choose Graph RAG if your specific use cases prioritize both facts and their relationships, as well as tracing the reasoning path is important.
When should you choose traditional RAG?
Traditional RAG proves useful in the following situations:
- Your dataset is primarily unstructured text. If your AI application mostly extracts data from product documentation, customer support guides, policies, or similar knowledge bases, choose traditional RAG.
- Queries are single-hop and direct. Select traditional RAG if you just want to handle simple, direct questions.
- You prioritize speed and simplicity over reasoning. Traditional RAG shines if your specific use cases consider high-speed search and retrieval more important.
- Explainability isn’t necessary. If showing the extracted text chunks is enough, choose a traditional RAG system.
In short, traditional RAG works best when you primarily need fast, reliable lookups and your data doesn’t need complex reasoning across various documents.
When to use hybrid
However, you can combine two RAG approaches to reach the best value if you need the speed of traditional retrieval for most queries but sometimes require the relationship-aware reasoning of Graph RAG.
For example, a help desk might use traditional RAG to answer simple “how-to” questions. But it can leverage a graph-based layer to search for root-cause issues or cross-product dependencies. This hybrid approach reduces computing costs while preserving deep insights for some crucial tasks.
Additionally, if you’re new to RAG, experiment with traditional value first to get its immediate value. Then, you can add a graph component for high-value tasks (e.g., regulatory reporting or fraud analysis) without redesigning the whole system.
Conclusion
RAG plays an increasingly important role in improving the capabilities of LLMs and reducing their hallucinations. Although the concept was newly introduced in 2020, it quickly received attention and adoption across sectors. Along with that is the evolution of RAG best practices over the years, from traditional RAG to Graph RAG.
This blog post has given a complete view of the key differences between Graph RAG vs traditional RAG. Understanding these different aspects helps you choose the right architecture for your AI application.
And if you want a long-term partner in the AI development journey, consider Designveloper!
Designveloper stands out as a top-tier software development and IT consulting firm in Vietnam. Our team brings a wide range of technical expertise to the table, covering 50+ modern technologies. So, we’re capable of delivering robust, high-quality AI solutions that integrate seamlessly and securely with your internal systems.
We’re also ahead of the curve with tools like LangChain and OpenAI, letting us build conversational bots that actually respond with context rooted in your up-to-date, verified data. Through RAG, we pack our bots with features clients actually care about: memory for multi-turn conversations, API hooks for real-time data, the works.
Our AI solutions are proven to help businesses connect with their ideal customers and get solid feedback. With over 200 successful projects under our belt and real-world experience using frameworks like SCRUM and Kanban, we’re confident in delivering projects on time and on budget.
Reach out to us for a detailed consultation about your RAG project! We’re here to help your business move forward with AI that actually delivers.
Also published on

Share post on










Read more topics










You may also like

7 Key Differences Between Agentic AI vs Generative AI (GenAI)
7 Key Differences Between Agentic AI vs Generative AI (GenAI) Published February 10, 2026
What Is Agentic AI? Benefits, Architecture and How It Works
What Is Agentic AI? Benefits, Architecture and How It Works Published February 10, 2026
10+ Best Vibe Coding Tools for Beginners in 2026
10+ Best Vibe Coding Tools for Beginners in 2026 Published December 25, 2025











